Discover how Google revolutionized the internet by shifting search from simple word matching to complex systems of relevance, authority, and trust. Learn how this shift laid the foundation for the modern web and modern search optimization.
15 min read
Foundations
Visual diagram
A graph showing PageRank-style authority flowing across a small set of linked pages.
Section 1 of 17
Introduction
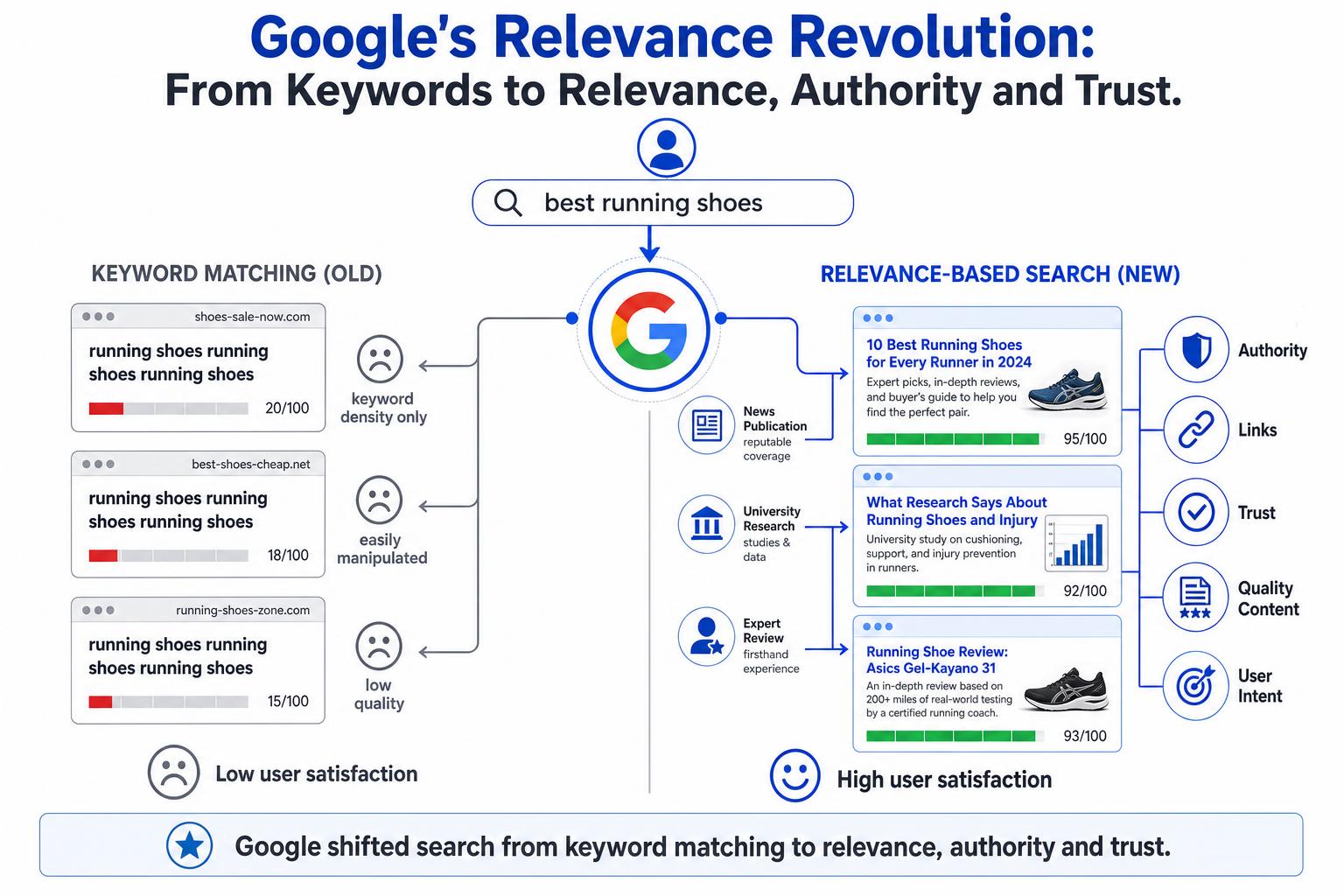
Imagine walking into a massive library with millions of books, but there is no librarian and no catalog system. The books are piled everywhere, from the floor to the ceiling. If you want a book about gardening, your only option is to yell the word "gardening" into the room and hope the right book magically floats to the top of a pile. In the early days of the internet, finding information felt exactly like this.
Before Google came along, early search engines were little more than digital filing cabinets. They were easily confused, easily tricked, and incredibly frustrating to use for everyday people. Finding a basic answer often meant clicking through pages of completely useless, broken, or spammy websites.
Then, a revolution happened. A new way of organizing the internet was born, fundamentally changing how humans consume information. In this lesson, we are going to explore how Google fixed the broken search experience. We will journey through the history of search, understand the shift from simple word-matching to complex understanding, and learn the foundational concepts of relevance, authority, and trust. You do not need any technical background to understand this—by the end, you will see exactly how search engines decide what makes one web page better than another.
Introduction
Assessment: Google's Relevance Revolution
Pass at 70%.
1. How did Google's early search algorithm primarily determine the importance of a web page?
2. In the context of search engines, what does "relevance" mean?
3. Why do search engines prioritize trust and authority when ranking websites?
4. What is "user intent" in search?
5. A user searches for "how to bake chocolate chip cookies." Which page is a search engine most likely to rank highly?
6. You run a small blog about healthy eating. Which link would provide the strongest signal of authority to a search engine?
7. How might a search engine determine if a user was satisfied with a search result?
8. As search evolves from traditional links to AI-driven answers, how does the concept of "relevance" fundamentally change?
9. Why is establishing your brand as a trusted authority even more critical for AI visibility than for traditional search?
10. How do modern AI search engines handle "user intent" differently than early search algorithms?