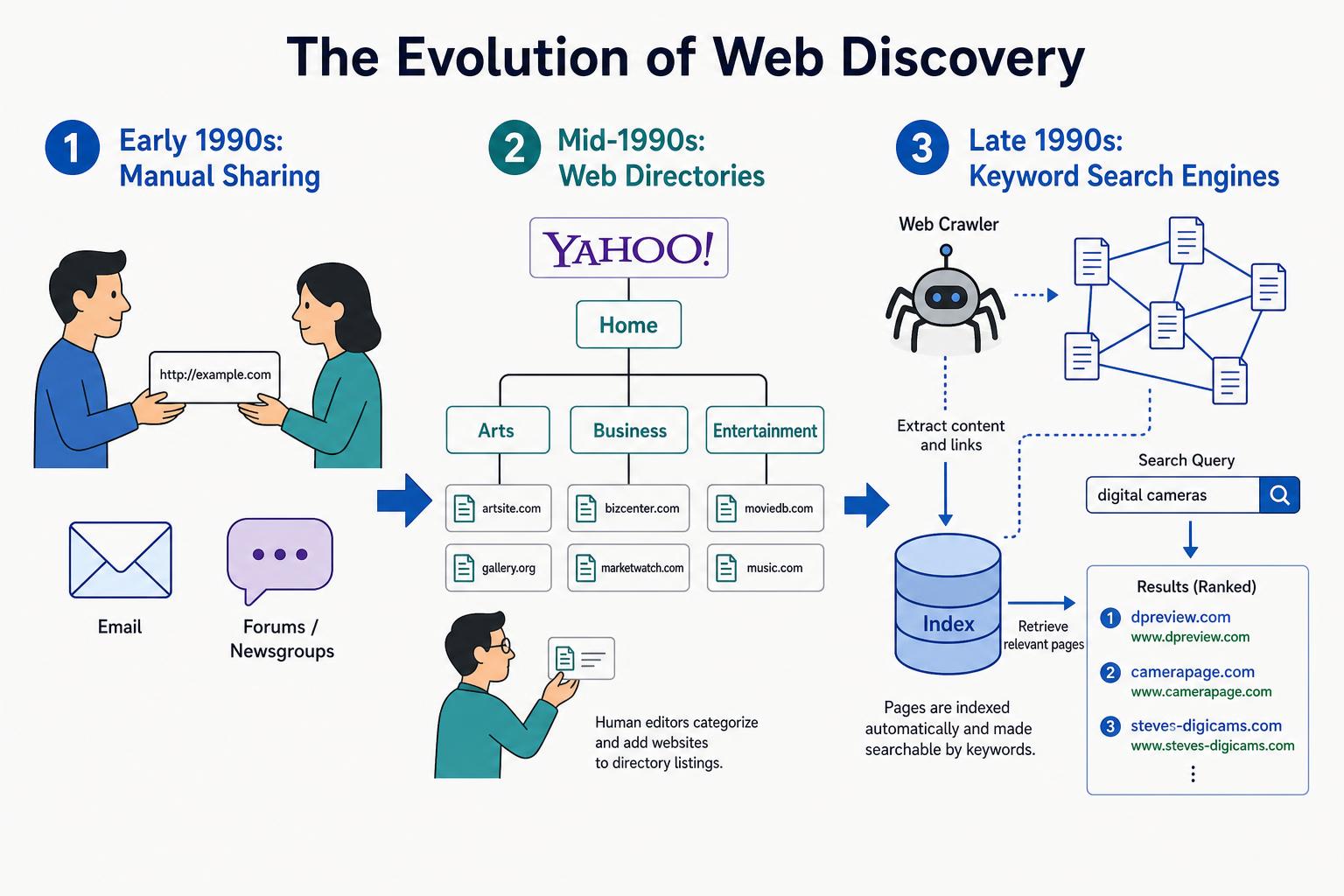
Discover the 'Wild West' of the early web. This lesson explores how people found information before Google, from manual link sharing to the rise and fall of human-curated web directories like Yahoo!.
12 min read
Foundations
Visual diagram
Section 1 of 9
Introduction
Learning Objectives
By the end of this lesson, you will be able to:
Describe how people found websites before modern search engines.
Explain the role and structure of early web directories, using Yahoo! as an example.
Define what a basic, keyword-based search engine was and how it worked.
Understand the limitations of these early discovery methods.
Connect the historical challenge of 'getting found' to the modern field of AI Visibility.
Introduction
The Early Internet Quiz
Pass at 70%.
1. Imagine you are using the internet in 1994. What would have been the biggest challenge in finding information about a specific topic, like classic cars?
2. Before search engines became popular, web directories like Yahoo! were a primary way to find information. What was the fundamental difference between a directory and a modern search engine?
3. A student is looking for a recipe for chocolate chip cookies using a 1996-era web directory. Which user behavior best describes how they would find it?
4. Why did the human-curated directory model, despite its initial success, ultimately fail to keep up with the growing internet?
5. In the context of early search engines, what is the most accurate analogy for an 'index'?
6. A web crawler's primary job is to discover and read information on the web. How does a crawler typically move from one page to the next to discover new content?
7. Early search engines, like AltaVista, ranked pages primarily on ''keyword density'' (how often a search term appeared on a page). What was a major negative consequence of this simple ranking system?
8. If you were the owner of a website in 1996 trying to get visibility, which strategy would have been the most logical, based on the technology of the time?
9. The shift from human-curated directories to automated search engines represents a fundamental change. What core problem did automation solve that humans could not?
10. Considering the journey from manual sharing to keyword search, what is the most important lesson this history teaches us about the future of finding information (like with AI)?