Master the technical deployment of llms.txt, XML sitemaps, and RSS/Atom feeds to prioritise critical content and context for AI crawlers and Large Language Models.
12 min read
Foundations
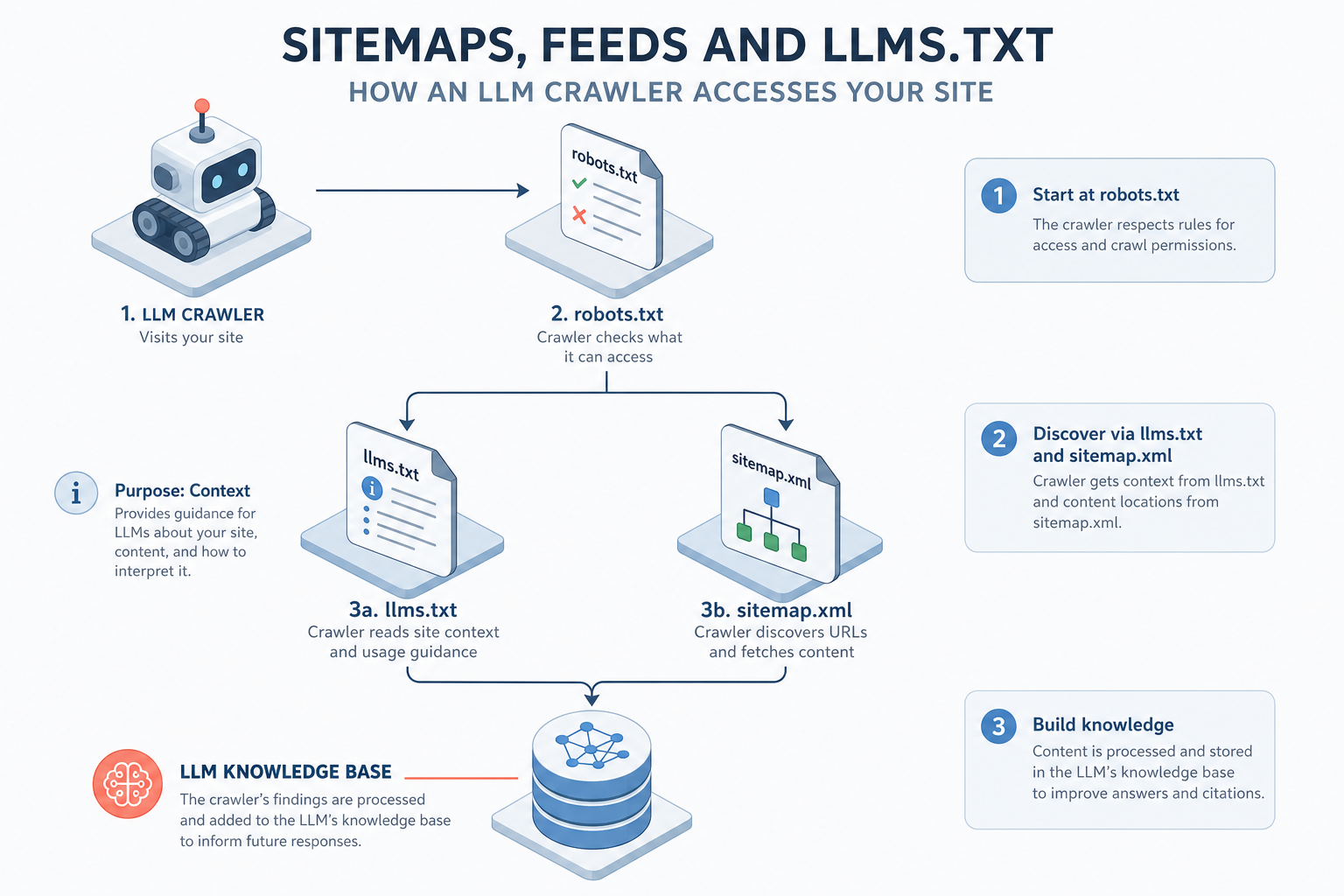
Visual diagram
A flowchart showing how an LLM crawler accesses a site, starting at robots.txt, then bifurcating to llms.txt for context and sitemap.xml for data, leading to the LLM Knowledge Base.
Section 1 of 10
Introduction to AI-Centric Discoverability
In the traditional search landscape, XML sitemaps were primarily a tool to help Googlebot discover URLs on large or complex sites. In the era of Generative Search and AI visibility, we must expand our definition of 'discoverability'. It is no longer just about ensuring a URL is indexed; it is about ensuring the right content is prioritised, contextualised, and formatted for Large Language Model (LLM) ingest.
This lesson explores the trifecta of machine-readable files: the evolving XML sitemap, the rejuvenated role of RSS/Atom feeds for real-time training, and the emerging standard of the llms.txt file. By mastering these, you ensure that AI agents spend their limited crawl budgets on your highest-value data rather than low-quality boilerplate.
Introduction to AI-Centric Discoverability
Lesson Quiz
Pass at 70%.
1. Where should the llms.txt file be located on a website?
2. What is the primary format used for the content within an llms.txt file?
3. Which sitemap tag is most critical for reducing AI 'hallucinations' by signalling fresh data?
4. How does llms.txt differ from robots.txt?
5. Why are full-text RSS feeds preferred over snippet-only feeds for AI visibility?
6. What is 'llms-full.txt' used for?
7. Which bot is specifically associated with OpenAI's search capabilities?
8. What should be the 'High Priority' focus for AI-centric sitemaps?
9. In the context of AI, what is a 'polling-based' discovery mechanism?
10. If you want an AI to avoid including a page in its training data, where is the first place to check?