Master the technical methods for confirming AI crawler access through server log analysis, User-Agent verification, and real-time probe testing to ensure content reaches LLM training sets.
12 min read
Foundations
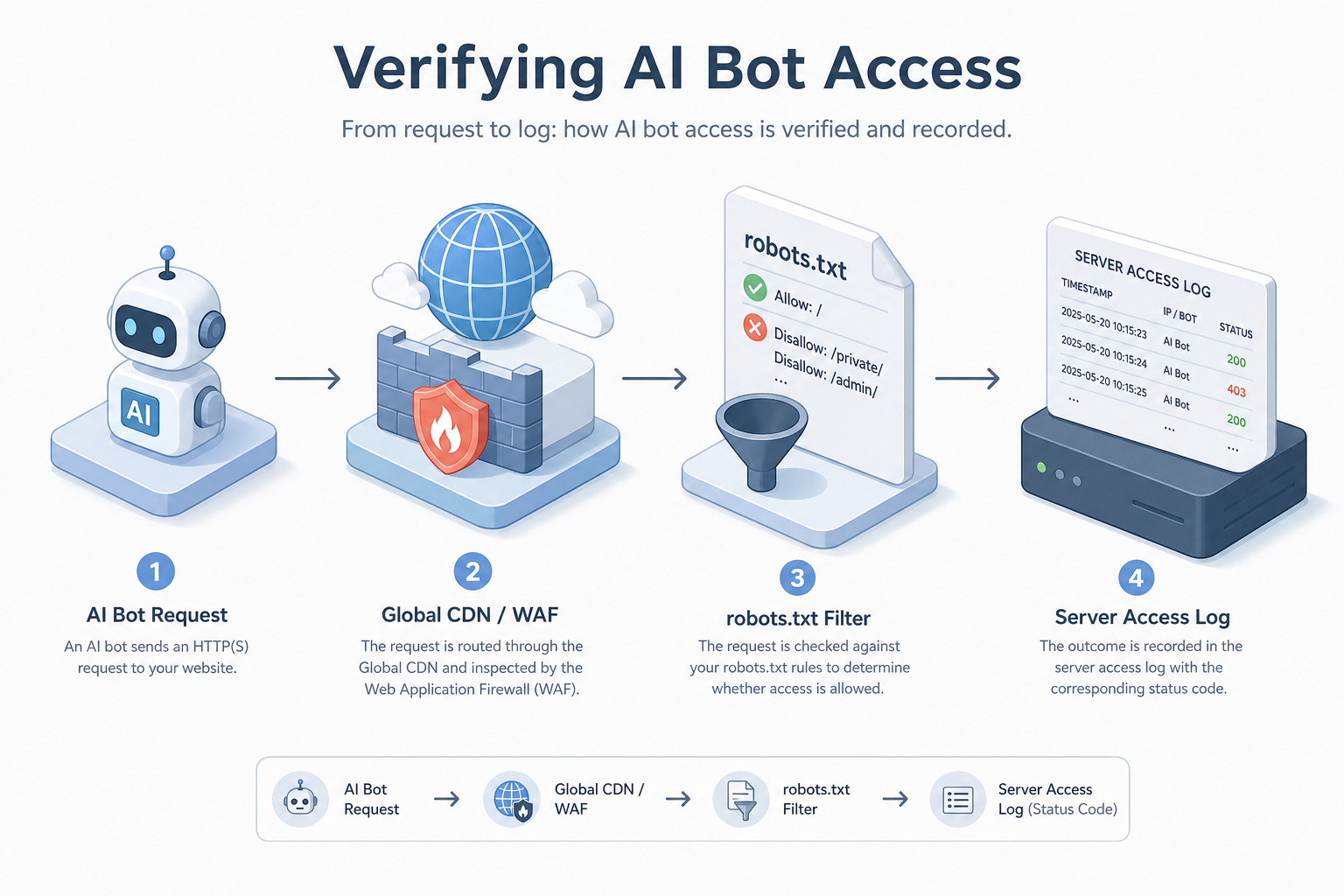
Visual diagram
A flowchart showing a request from an AI Bot hitting a Global CDN/WAF, passing through a robots.txt filter, and finally being recorded in a Server Access Log with a status code.
Section 1 of 9
Introduction
Before content can be surfaced in an AI-generated response or a Generative Engine Optimization (GEO) result, the underlying AI bot must be able to crawl and ingest the data. While most SEO practitioners are familiar with Googlebot, the ecosystem for AI visibility involves a distinct set of crawlers with different behaviors, IP ranges, and retry cadences. If your robots.txt or server-side firewall (WAF) is inadvertently blocking these agents, your visibility efforts are void. This lesson provides a technical framework for verifying that AI bots can reach your content using server logs and live probes.
Introduction
Lesson Quiz
Pass at 70%.
1. Which server response code indicates that an AI bot is being actively blocked by your server or firewall?
2. Why shouldn't you rely solely on User-Agent strings for verifying AI bots in logs?
3. What is the primary function of the 'Google-Extended' token in robots.txt?
4. Which command-line tool is commonly used to manually 'probe' a URL with a specific User-Agent?
5. If you see a 429 status code in your logs specifically for GPTBot, what is the most likely issue?
6. Which bot is specifically used for OpenAI's real-time web search features?
7. Where is the first place you should check if you suspect a CDN is blocking AI bots?
8. What does a 304 Not Modified status code imply regarding your crawl budget?
9. Which of these is a major crawler for training data used by multiple AI companies?
10. What is the purpose of 'Allow' directives in robots.txt for AI bots?