Understand how client-side rendering (CSR) and complex JavaScript frameworks hinder AI crawlers and LLM data fetchers from indexing and citing your core content.
12 min read
Foundations
Visual diagram
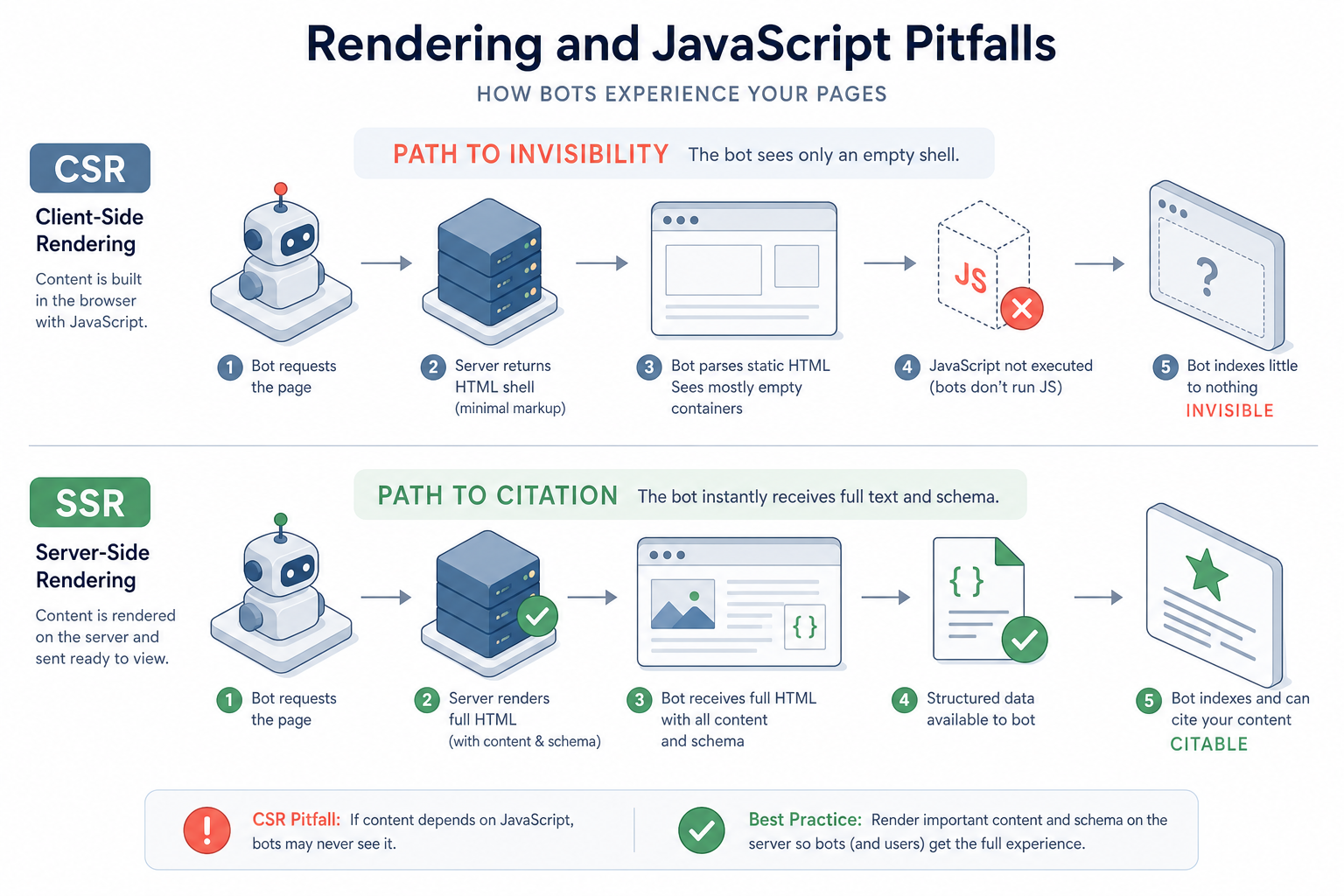
A workflow diagram showing the 'Path to Invisibility' for CSR where a bot sees only an empty shell, contrasted with the 'Path to Citation' for SSR where a bot instantly receives full text and schema.
Section 1 of 9
The Visibility Gap in the Age of AI
While traditional search engines like Google have become increasingly adept at rendering JavaScript, the same cannot be assumed for the burgeoning ecosystem of AI models and 'Generative Experience' (GE) crawlers. In the AI Visibility Practitioner's world, we distinguish between standard SEO crawling and AI fetchers used by Large Language Models (LLMs) like GPT-4, Claude, and Perplexity. These bots often operate under strict resource constraints, leading to a 'rendering gap' where your content is physically on the page for a human user but effectively invisible to the AI that needs to cite it.
This lesson explores why relying heavily on Client-Side Rendering (CSR) is a high-risk strategy for AI visibility and how to audit your site to ensure your data is 'scraper-ready' and easily digestible by the engines driving the next generation of search.
The Visibility Gap in the Age of AI
Lesson Quiz
Pass at 70%.
1. What is the primary reason AI fetchers might fail to see content on a React-based SPA?
2. How does 'Hydration' in frameworks like Next.js help AI Visibility?
3. Which of these features is most likely to be 'invisible' to an AI crawler?
4. What is the 'No-JS' litmus test used for?
5. Why is the Shadow DOM a potential pitfall for AI discoverability?
6. If a page uses infinite scroll to show product reviews, how will an AI bot likely react?
7. What is the 'Visibility Gold Standard' mentioned in the lesson?
8. Which HTTP status code might an AI bot receive if it fails to trigger a JS-driven redirect?
9. Why does DOM size (number of nodes) matter for AI Visibility?
10. What should a Practitioner suggest if a client refuses to move away from a CSR architecture?