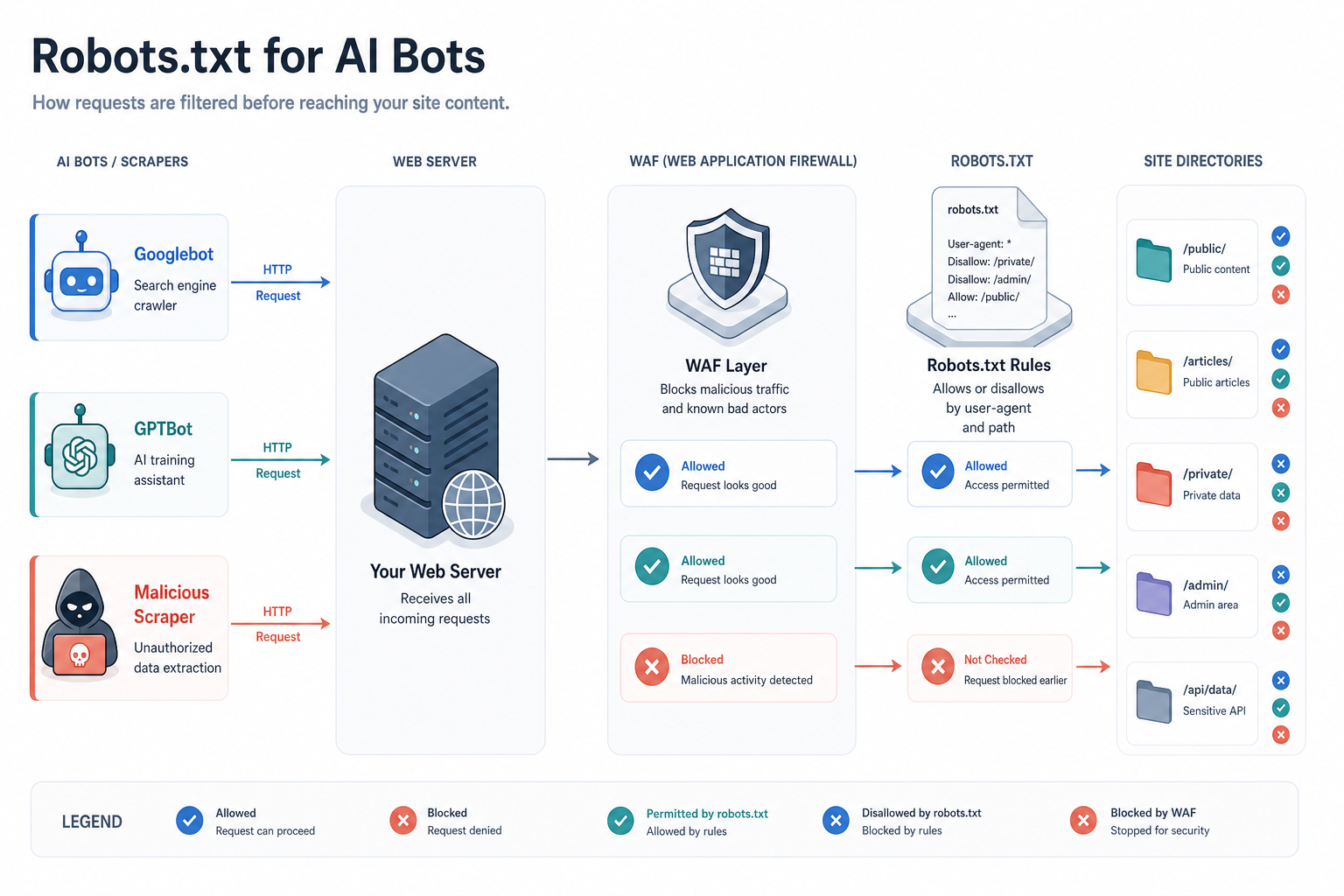
Introduction to AI Bot Management
In the era of AI-driven search and Answer Engine Optimisation (AEO), the role of robots.txt has evolved from a simple indexing tool into a critical strategic asset. While traditional SEO focused on Googlebot and Bingbot, the modern practitioner must now manage a diverse ecosystem of AI agents, including GPTBot (OpenAI), ClaudeBot (Anthropic), and PerplexityBot. This lesson provides a technical framework for configuring your root directory to control how LLM (Large Language Model) developers access your data.
Controlling AI bots is not merely about blocking or allowing; it is about selective visibility. As an AI Visibility Practitioner, your goal is to ensure that your high-quality, branded content is accessible for training and real-time retrieval while protecting sensitive data, proprietary tools, and low-value thin content that could dilute your brand's representation in AI outputs.