Master the technical pathways AI crawlers use to discover, fetch, and process content for Large Language Models and Generative Search engines.
12 min read
Foundations
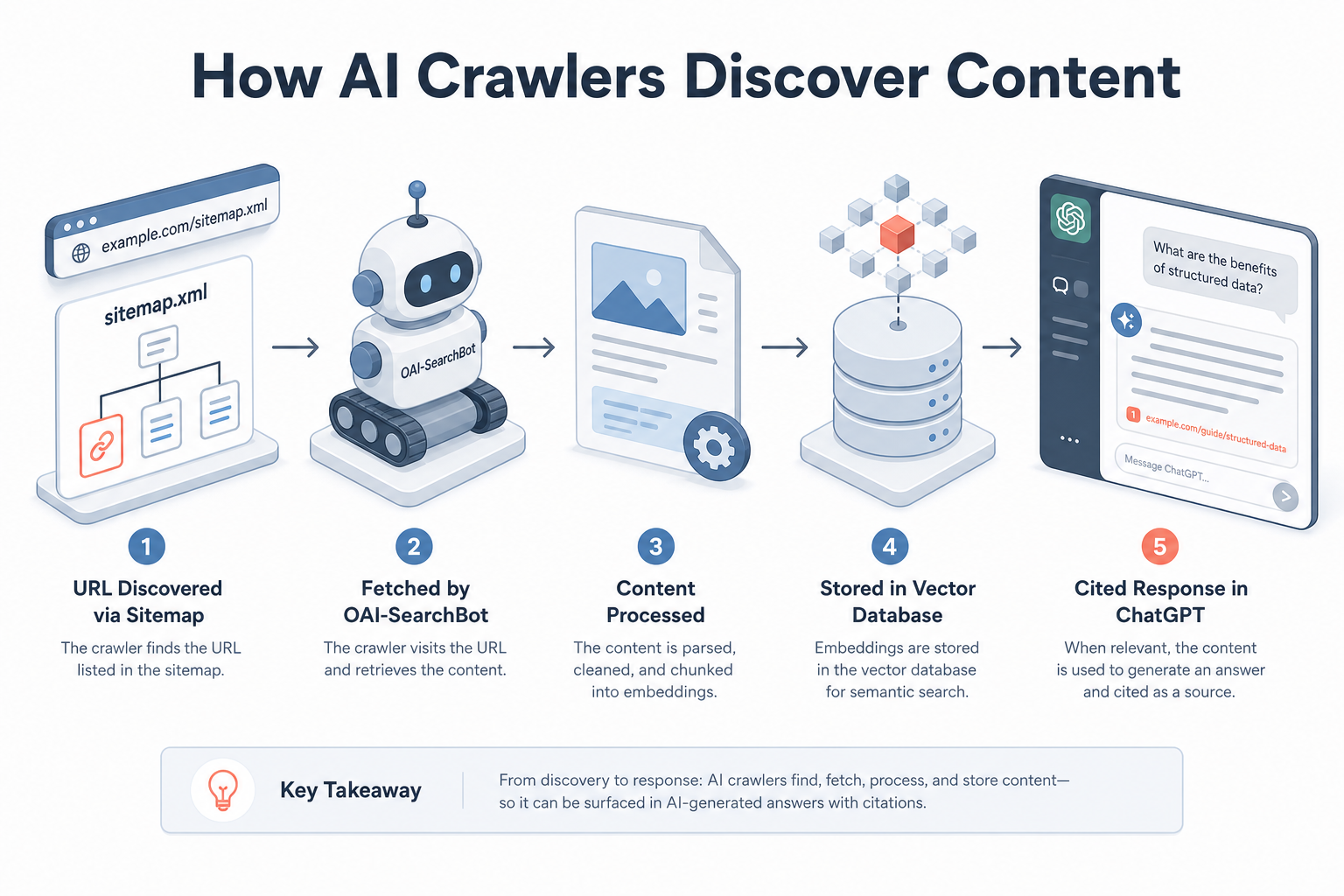
Visual diagram
A flowchart showing a URL being discovered via a sitemap, fetched by OAI-SearchBot, processed through a vector database, and finally appearing as a cited response in a ChatGPT interface.
Section 1 of 10
Introduction
For content to appear inside a generative AI response—whether via ChatGPT, Perplexity, or Google’s Search Generative Experience (SGE)—it must first be discovered. While traditional SEO focuses on the Googlebot crawl, the AI ecosystem involves a diverse range of ‘agents’ with different behaviours, frequencies, and prioritisation logic. This lesson breaks down the technical journey from a server request to an AI index, providing practitioners with the knowledge to ensure their content is accessible to both traditional bots and the specific crawlers powering the next generation of discovery.
Introduction
Lesson Quiz
Pass at 70%.
1. Which bot is specifically used by OpenAI for real-time search functionality in ChatGPT?
2. Why is CCBot (Common Crawl) important for AI visibility?
3. What is 'vectorisation' in the context of AI indexing?
4. Which of these is a likely result of blocking 'GPTBot' in robots.txt?
5. How do AI agents typically handle content hidden behind JavaScript 'read more' buttons?
6. What is the primary risk of an aggressive CDN/WAF for AI visibility?
7. What role does Semantic HTML (like <article>) play in AI discovery?
8. If a site has a hard paywall, what is the most likely outcome for AI bots?
9. What is 'Crawl Budget' in the context of AI?
10. Which technology is recommended to ensure AI crawlers see JavaScript-rendered content reliably?