Master the specific Schema.org types and properties that enhance Large Language Model (LLM) comprehension and entity linking for AI-driven search results.
12 min read
Foundations
Visual diagram
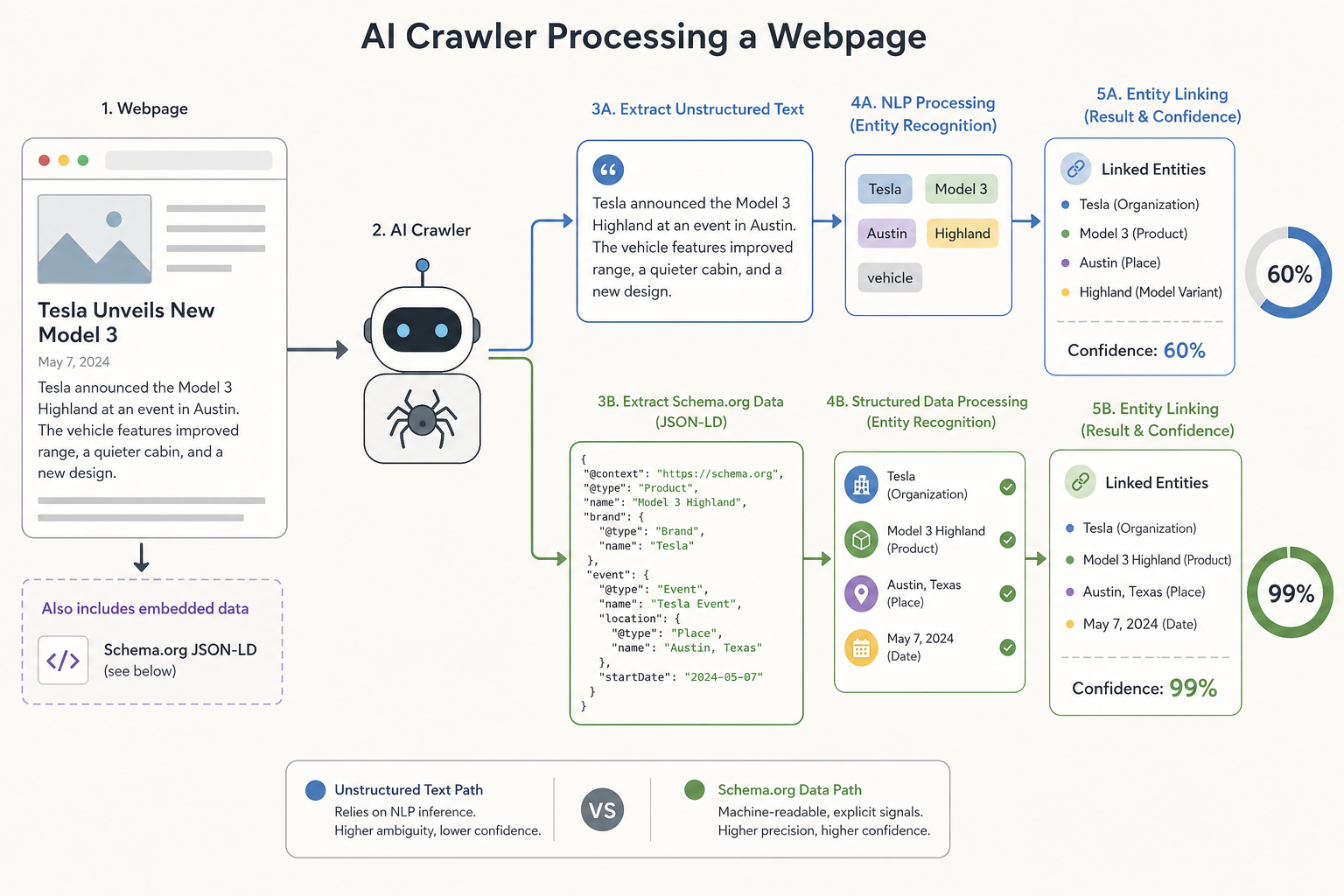
A workflow diagram showing an AI crawler processing a webpage: one path shows unstructured text being processed with 60% confidence, while the other shows Schema.org data providing 99% confidence for entity linking.
Section 1 of 10
Introduction to Schema for AI Visibility
In the era of Generative Search Experiences (SGE) and AI Overviews, Schema.org structured data has evolved from a rich-snippet tool into a primary source of ground truth for Large Language Models (LLMs). While traditional SEO often focuses on generating star ratings in SERPs, the AI Visibility Practitioner focuses on Entity Disambiguation. For an AI to recommend your client as a solution, it must first understand exactly what that client is, who they serve, and how they relate to other verified entities on the web. This lesson provides a tactical guide to the schema types that move the needle in AI visibility.
Introduction to Schema for AI Visibility
Lesson Quiz
Pass at 70%.
1. Which Schema.org property is most effective for linking a website entity to its established entry in a database like Wikidata?
2. What is the primary benefit of using the '@id' property in your JSON-LD?
3. Why should you use 'Person' schema for authors rather than a simple text string?
4. Which property would you use to tell an AI which specific topics an Organization is an expert in?
5. True or False: The Schema Markup Validator is preferred over the Rich Results Test for AI Visibility auditing.
6. In the context of AI, what does 'Entity Disambiguation' mean?
7. Which property is most useful within a 'WebPage' type to signal the primary subject matter to an AI?
8. What happens if your schema says one thing but the visible page content says another?
9. Which schema type should be used for a B2B software offering to help AI comparison tools?
10. How do AI answer engines typically use FAQPage schema?