Master the audit of brand visibility across key entity repositories including Wikidata, Wikipedia, and Google’s Knowledge Graph to build a robust foundation for AI-driven discovery.
12 min read
Foundations
Visual diagram
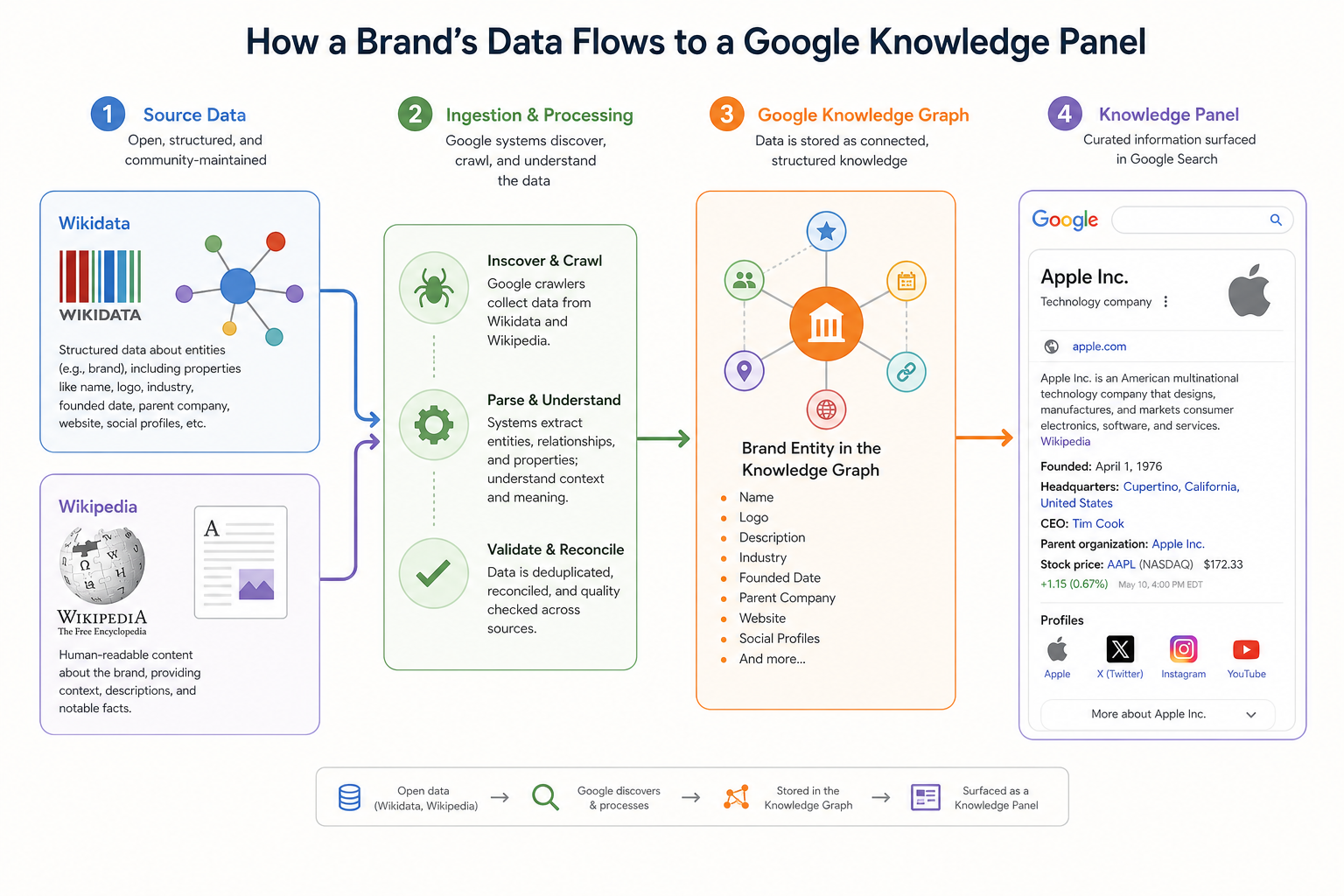
A flow chart showing how a brand's data flows from Wikidata and Wikipedia into the Google Knowledge Graph, resulting in a Knowledge Panel.
Section 1 of 7
Introduction
Entity analysis is the foundation of modern search visibility. As we transition from strings to things, search engines and Large Language Models (LLMs) no longer just index keywords; they attempt to understand the relationships between concepts, organisations, people, and places. To be visible in AI-generated answers and Google’s Knowledge Panels, your brand must be recognised as a distinct entity within the global Knowledge Graph. This lesson provides a systematic framework for auditing a brand’s presence across the three most influential entity nodes: Wikidata, Wikipedia, and the Google Knowledge Graph.
Introduction
Lesson Quiz
Pass at 70%.
1. What is the primary difference between Wikidata and Wikipedia for an entity audit?
2. Which Wikidata property is essential for defining what a brand actually 'is' (e.g., a company)?
3. What does a Google Knowledge Graph ID starting with '/g/' typically indicate compared to '/m/'?
4. If a brand has no Wikipedia page, how can it still build entity trust?
5. What does the 'resultScore' in the Google Knowledge Graph API represent?
6. Which tool would you use to see the 'history' of an entity's narrative changes?
7. What is 'entity reconciliation'?
8. Why is the 'official website' (P856) property crucial in Wikidata?
9. When auditing a Knowledge Panel, what does the absence of a 'Claim this knowledge panel' button suggest?