Master the fundamentals of entities and knowledge graphs to bridge the gap between traditional keyword-based SEO and semantic AI visibility.
12 min read
Foundations
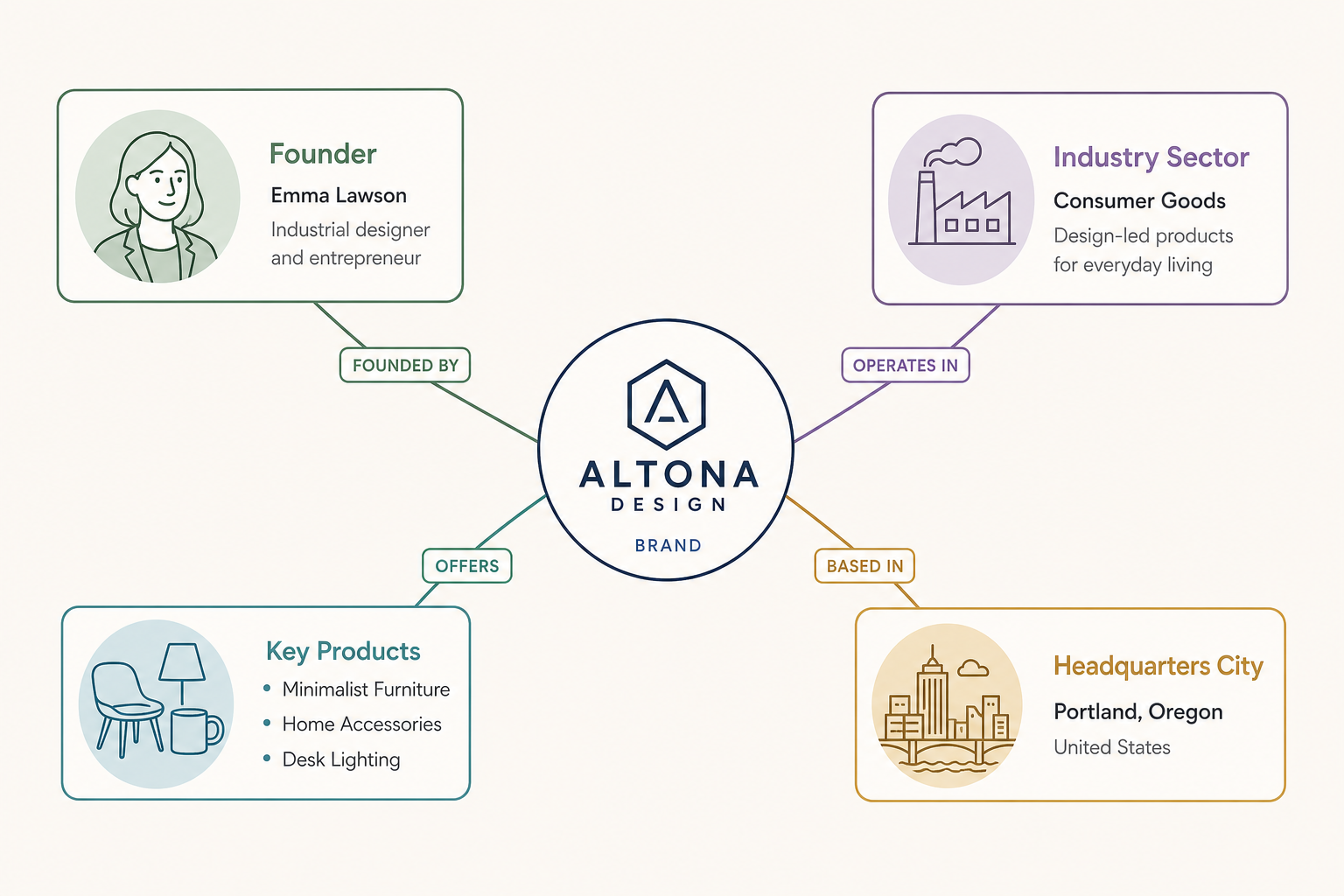
Visual diagram
A network map showing a central brand node connected by labelled lines (edges) to related entities like 'Founder', 'Industry Sector', 'Key Products', and 'Headquarters City'.
Section 1 of 11
Introduction
To the modern search engine and the Large Language Model (LLM), the world is no longer a collection of strings—sequences of characters like 'London' or 'Apple'. Instead, the world is a map of things: entities. An entity is a singular, unique, well-defined, and distinguishable object or concept. In this lesson, we will move beyond the basic definition of an entity to understand how Generative Engine Optimisation (GEO) and AI visibility rely on the relationships between these entities within Knowledge Graphs. For a practitioner, understanding entities is the difference between ranking for a keyword and being 'known' by an AI as an authority in a specific niche.
Introduction
Lesson Quiz
Pass at 70%.
1. What is the primary difference between a 'string' and a 'thing' in SEO?
2. In a Knowledge Graph, what does an 'Edge' represent?
3. Which Schema.org property is used to link a local entity to its corresponding entry on Wikidata or Wikipedia?
4. Why are LLMs considered different from traditional Knowledge Graphs?
5. What is 'Entity Disambiguation'?
6. Which of these is a 'Triple' in the context of Knowledge Graphs?
7. How does 'Entity Salience' affect AI visibility?
8. Which tool would a practitioner use to verify how Google's NLP categorizes their page's entities?
9. What is the benefit of including 'About' and 'Mentions' in your Article schema?