Develop a robust methodology for maintaining, versioning, and executing a core prompt set across multiple LLMs to track brand visibility consistently over time.
12 min read
Foundations
Visual diagram
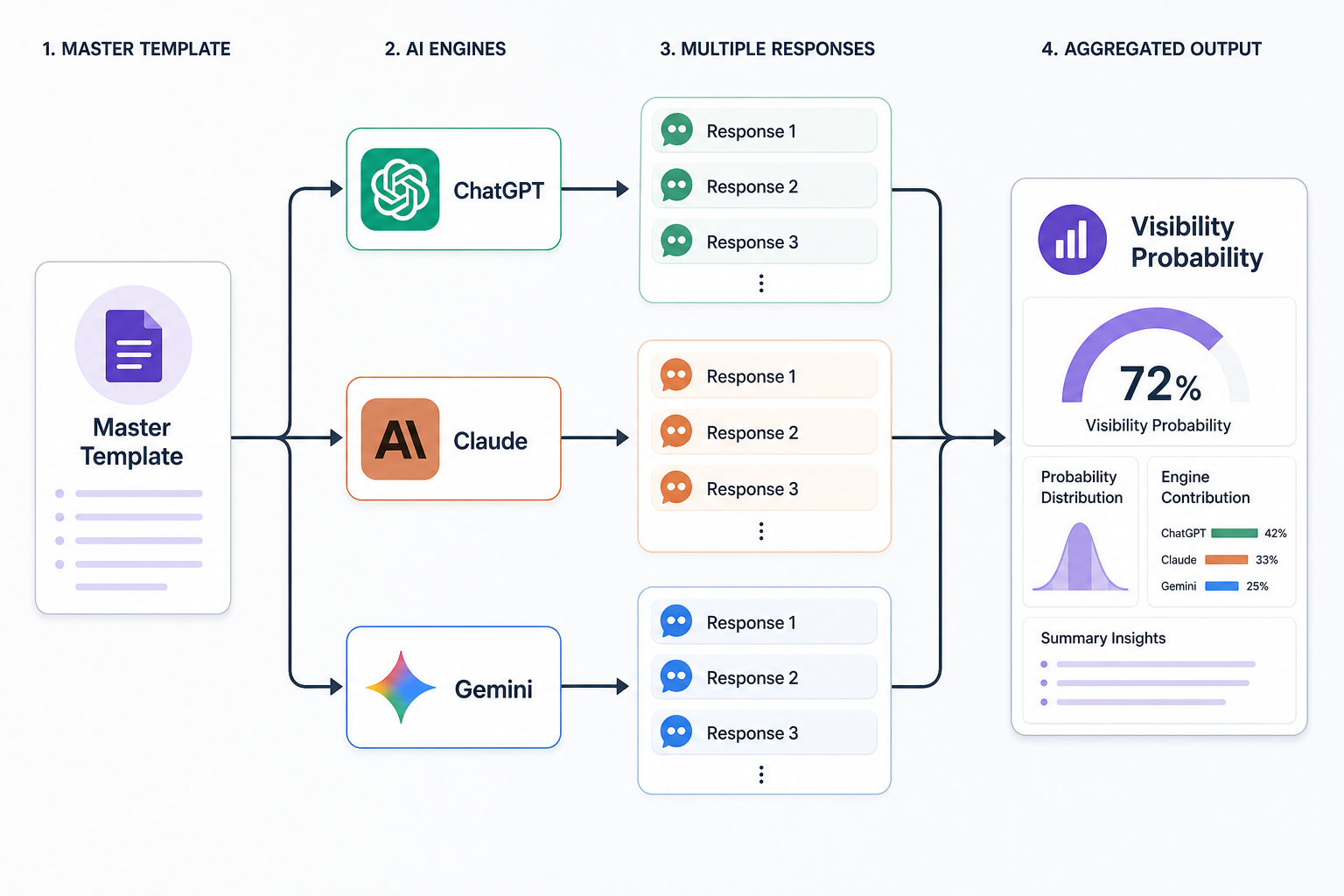
A flow chart showing a 'Master Template' splitting into three AI engines (ChatGPT, Claude, Gemini), each producing multiple responses that are then aggregated into a single 'Visibility Probability' dashboard.
Section 1 of 9
Introduction to Prompt Tracking
As an AI Visibility Practitioner, your ability to provide consistent data depends entirely on the stability of your measurement instruments. In the world of GEO (Generative Engine Optimisation), your 'instruments' are your prompts. Tracking brand visibility at scale is not as simple as checking a keyword on a search engine results page (SERP); it requires managing a matrix of variables including model versions, brand entities, and natural language nuances. This lesson focuses on the transition from ad-hoc prompting to a systemic, enterprise-grade prompt tracking framework.
Without a structured approach, visibility reports become 'noisy'. If a brand mention disappears, was it because of a change in the AI's weightings, or because you slightly altered the prompt phrasing? To provide actionable insights to clients, you must eliminate prompt variability and treat your queries as fixed assets across multiple engines like ChatGPT (GPT-4o), Claude 3.5, and Google Gemini.
Introduction to Prompt Tracking
Lesson Quiz
Pass at 70%.
1. What is 'Model Drift' in the context of prompt tracking?
2. Why is 'N-of-5' testing recommended for AI visibility tracking?
3. Which of these is a 'Category' level query?
4. What is the primary benefit of using variable-based prompt templates?
5. In prompt tracking, what does a 'Gold Standard' answer refer to?
6. When tracking at scale, why is it important to record 'Cited Sources'?
7. Which engine integration is currently unique to Google Gemini in visibility tracking?
8. What should a practitioner do if a brand's visibility drops after an AI model update?
9. What is the 'Visibility Ledger'?
10. Which of these is NOT a core bucket for a tracked prompt set?