Master the application of ICE and RICE frameworks specifically for AI Visibility, prioritising high-impact optimisations that align with LLM training cycles and user intent.
12 min read
Foundations
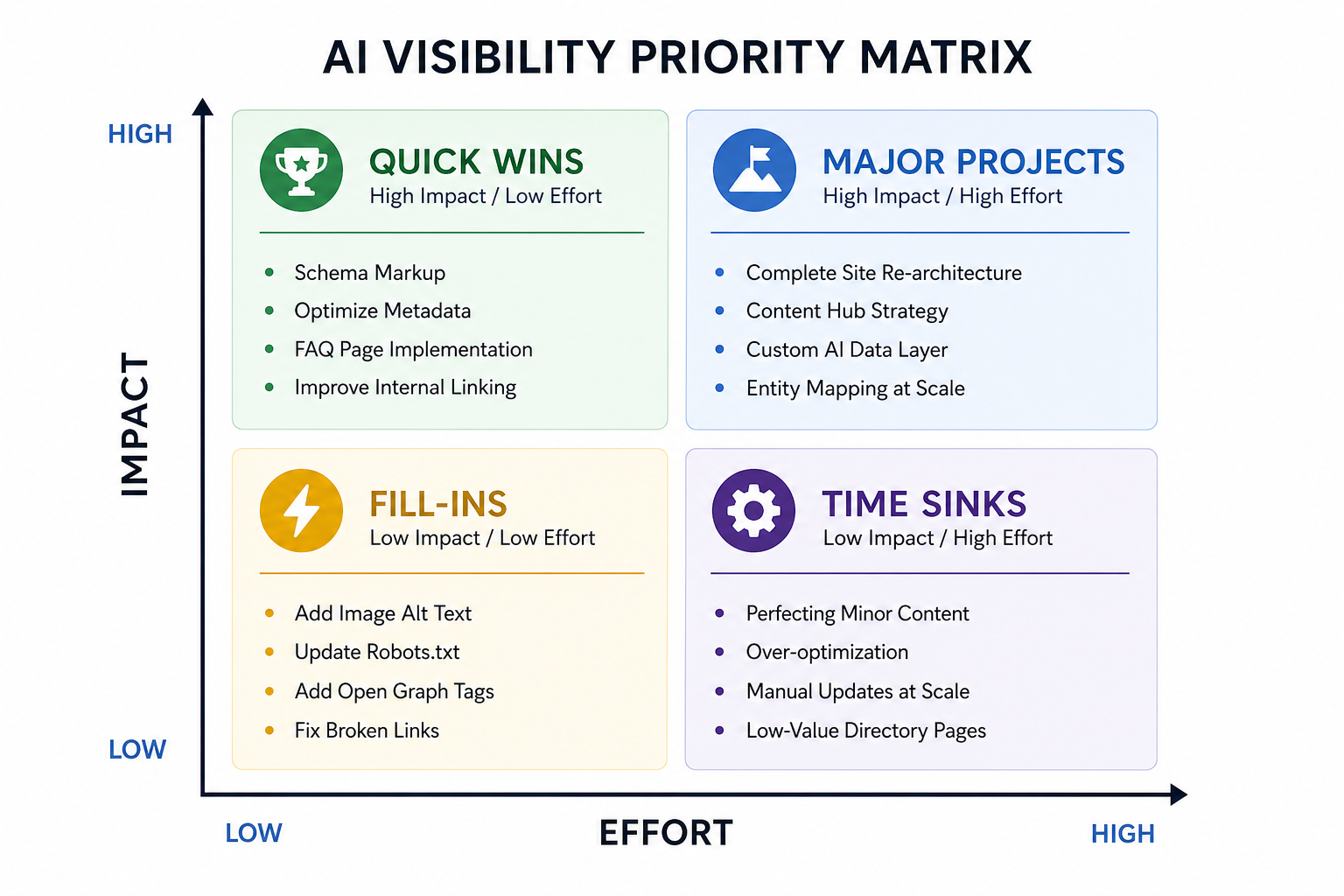
Visual diagram
A 2x2 Matrix showing Effort on the X-axis and Impact on the Y-axis, with specific AI Visibility tasks like 'Schema Markup' in the Quick Wins quadrant and 'Complete Site Re-architecture' in the Major Projects quadrant.
Section 1 of 9
Introduction
Transitioning from theoretical AI visibility to practical implementation requires a robust system for decision-making. In the fast-moving landscape of LLMs (Large Language Models) and Answer Engine Optimisation (AEO), practitioners often face a backlog of hundreds of potential fixes—from structured data overhaul to entity bridging. Without a structured prioritisation framework, marketing teams risk wasting resources on 'vanity' optimisations that do not move the needle on citations or sentiment. This lesson explores how to adapt proven frameworks like ICE and RICE to the unique constraints of AI visibility.
Introduction
Lesson Quiz
Pass at 70%.
1. What does the 'R' in RICE stand for in the context of AI visibility?
2. When using the ICE framework, how is the final score calculated?
3. Which task would likely fall into the 'Quick Win' quadrant of an Effort-Impact matrix?
4. If you have 100% confidence but the reach is zero, what is the RICE score?
5. What is a major difference between prioritising traditional SEO and AI visibility?
6. In the RICE framework, what is the recommended Impact score for a 'Massive' movement in visibility?
7. Why is 'Confidence' a critical metric for AI visibility tasks?
8. A task with high effort and low impact is categorised as a:
9. How should 'Effort' be measured in the RICE model?
10. Which of these would justify lowering a Confidence score for an AEO task?