This lesson establishes the essential software, data sources and monitoring environments required to measure and influence AI visibility across major LLMs and search engines.
12 min read
Foundations
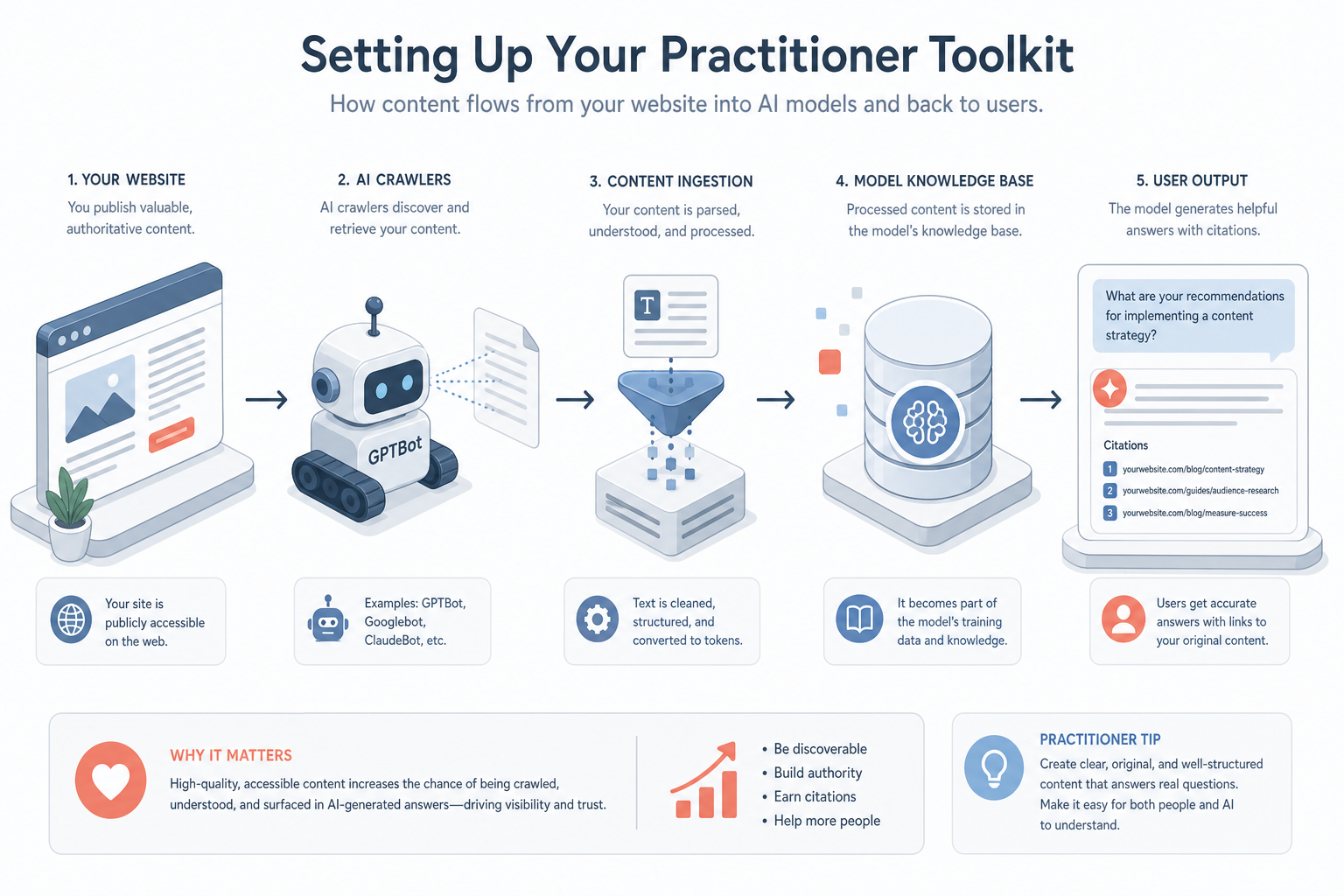
Visual diagram
A flowchart showing the flow of data from a website through AI crawlers (like GPTBot) into a model's 'Knowledge Base,' ending in a 'User Output' with citations.
Section 1 of 10
Introduction to the Practitioner Toolkit
Transitioning from foundational theory to practical application requires a structured environment. Unlike traditional SEO, where a handful of established tools like GSC, Ahrefs, or Semrush dominate, AI Visibility Optimization (AIVO) and Generative Engine Optimization (GEO) require a fragmented, multi-layered stack. You are no longer just monitoring a single search engine results page (SERP); you are monitoring probabilistic outputs, citation nodes, and the underlying data sets that feed Large Language Models (LLMs).
Setting up your practitioner toolkit is the first billable step in a client engagement. This lesson provides a blueprint for the accounts, browser environments, and data scrapers you need to provide data-driven insights.
Introduction to the Practitioner Toolkit
Lesson Quiz
Pass at 70%.
1. Why is it recommended to use a dedicated browser profile for AI visibility research?
2. Which specific AI engine is considered the most 'trackable' for citations due to its search-centric design?
3. What is the primary function of ‘GPTBot’ in the context of AI visibility?
4. Why would an intermediate practitioner need API keys for Google Vertex AI or OpenAI?
5. Which file should you check first to see if a site is intentionally excluding AI crawlers?
6. In the 'Mandatory Four' LLMs, why is Claude Pro included in the toolkit?
7. What role does 'Common Crawl' play in AI Visibility?
8. What is the benefit of using 'No-Code' tools like Make.com in an AI visibility audit?
9. When monitoring brand sentiment for AI, why are tools like ‘GummySearch’ (for Reddit) useful?
10. What does a 'Search Agent Switcher' extension help a practitioner do?