Master the technical identification of AI agents in server logs to predict visibility shifts before they appear in user-facing LLM results.
12 min read
Foundations
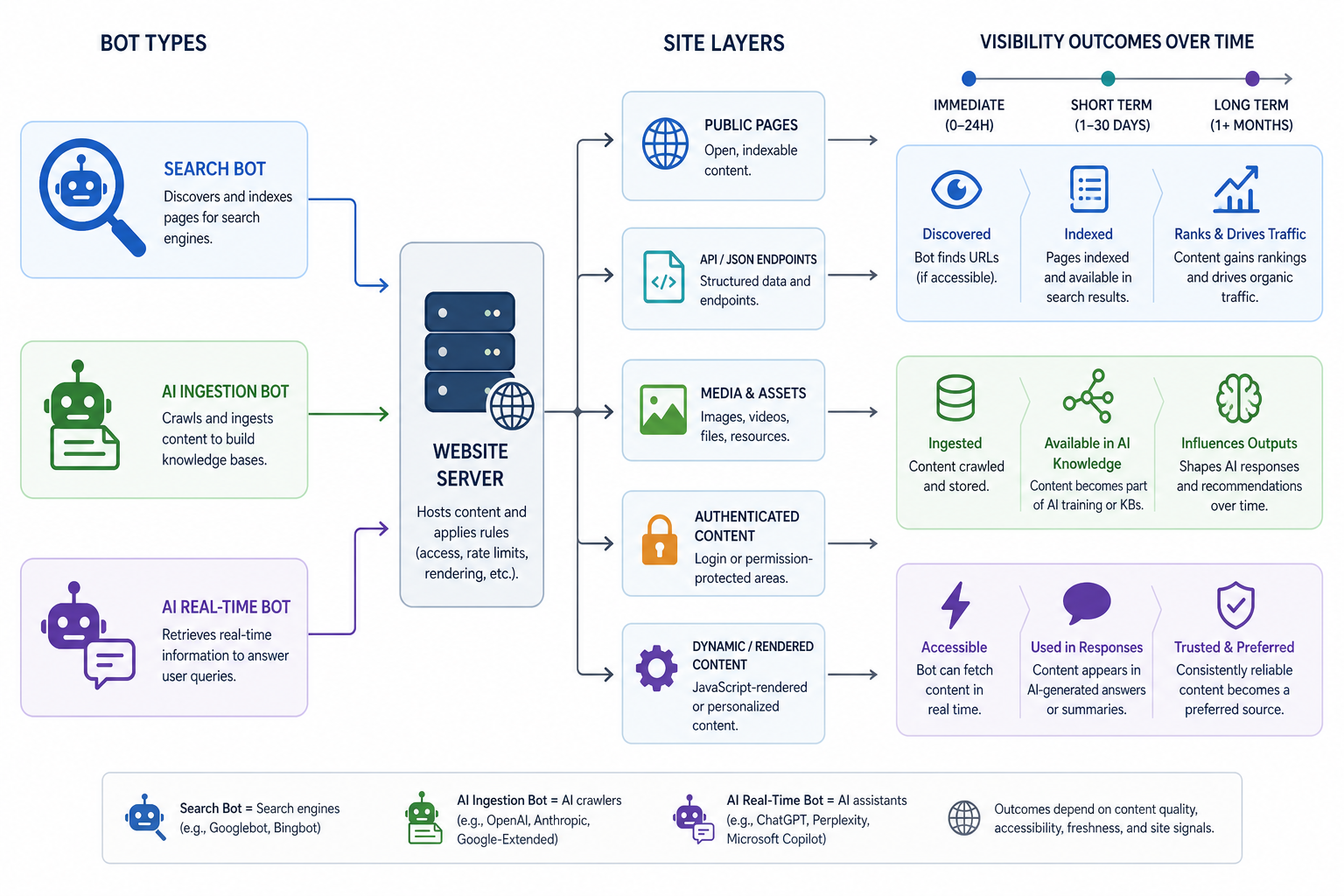
Visual diagram
A flowchart showing a website server in the centre, with three distinct bot types (Search, AI Ingestion, AI Real-time) interacting with various site layers and leading to a timeline of visibility outcomes.
Section 1 of 8
Introduction to AI Bot Monitoring
In the era of AI-driven search and generative engines, waiting for third-party rank trackers to show positions is a reactive strategy. To be proactive, an AI Visibility Practitioner must look at the source: server logs. When AI companies like OpenAI, Anthropic, or Perplexity refresh their knowledge bases, they crawl the web. By monitoring these crawls in real-time or near-real-time, you gain a leading indicator of when your content is being 'ingested' and integrated into LLM responses. This lesson covers how to identify these bots, distinguish them from legacy search crawlers, and use this data to forecast visibility gains.
Introduction to AI Bot Monitoring
Lesson Quiz
Pass at 70%.
1. Which OpenAI bot is used specifically for real-time web browsing triggered by a user's prompt?
2. If you see a 403 status code for GPTBot in your logs, what does this most likely mean?
3. How can you verify that a bot claiming to be 'ClaudeBot' is actually from Anthropic?
4. What is the primary purpose of monitoring CCBot activity?
5. Which response code indicates that an AI bot has checked your page but found no changes since the last crawl?
6. You see a massive spike in GPTBot activity followed by a total cessation. What does this likely indicate?
7. How does monitoring AI bots serve as a 'leading indicator'?
8. Why might a practitioner want to track the 'per-URL' crawl frequency of AI bots?
9. Which of these is NOT a legitimate AI crawler mentioned in the lesson?
10. If a site uses Cloudflare, where is the best place to find AI bot activity data?