Master the technical essentials of AI bot accessibility, focusing on robots.txt configurations, schema validation, and rendering efficiency for LLM crawlers.
12 min read
Foundations
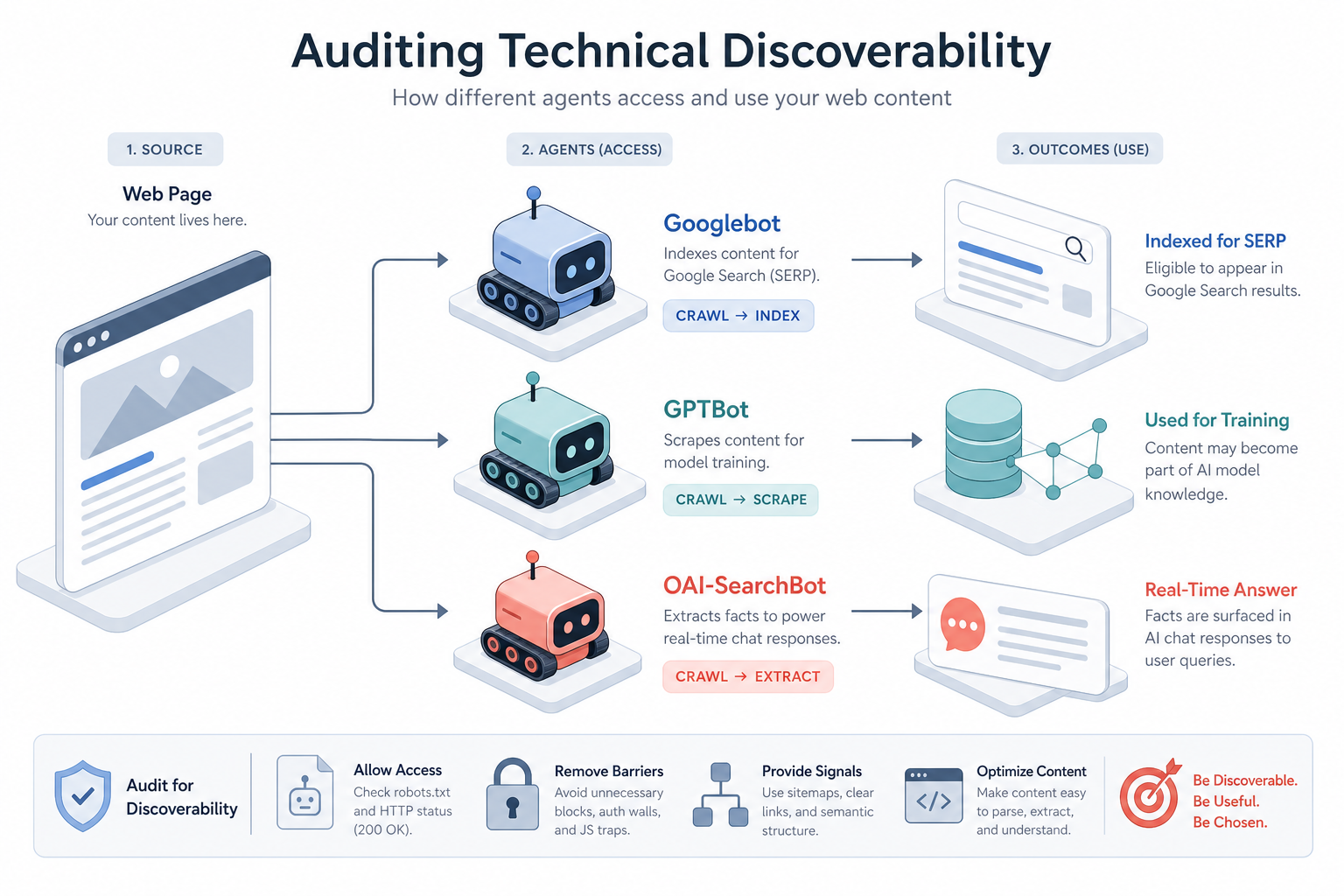
Visual diagram
A flowchart showing a web page being processed by three different agents: Googlebot (indexing for SERP), GPTBot (scraping for training), and OAI-SearchBot (extracting facts for a real-time chat response).
Section 1 of 9
Introduction to Technical Discoverability for AI
In the era of Generative Engine Optimisation (GEO), technical SEO has evolved beyond preparing pages for traditional search engines like Google or Bing. We now must ensure our content is architecturally sound for Large Language Model (LLM) agents and AI crawlers such as GPTBot, Claude-Bot, and OAI-SearchBot. Technical discoverability refers to the ability of these specific agents to crawl, render, and extract structured meaning from your web pages without friction. If an AI bot cannot parse your site efficiently, your brand will not appear in AI-generated summaries, even if your content is high quality.
Introduction to Technical Discoverability for AI
Lesson Quiz
Pass at 70%.
1. Which OpenAI bot is specifically used for the real-time search functionality within ChatGPT?
2. If your content is only visible after JavaScript execution, what is the primary risk for AI visibility?
3. What is the benefit of using 'sameAs' in your JSON-LD schema for AI visibility?
4. Why is 'Semantic HTML' (e.g., <article>, <nav>) important for AI engines?
5. In a robots.txt file, what does 'User-agent: *' apply to?
6. Which of these is a common 'AI Crawler' used for building large-scale open-source datasets?
7. If a site's Time to First Byte (TTFB) is very high, how might an AI bot react?
8. Which schema type would be MOST helpful for an AI trying to compare software features?
9. What is the main drawback of blocking 'GPTBot' while allowing 'OAI-SearchBot'?
10. A technical AI audit reveals that critical text is hidden behind a 'Click to Expand' accordion that uses JavaScript. What is the best recommendation?