Master the methodology for identifying seed URLs, defining prompt libraries, and selecting competitors to create a robust data foundation for AI visibility audits.
12 min read
Foundations
Visual diagram
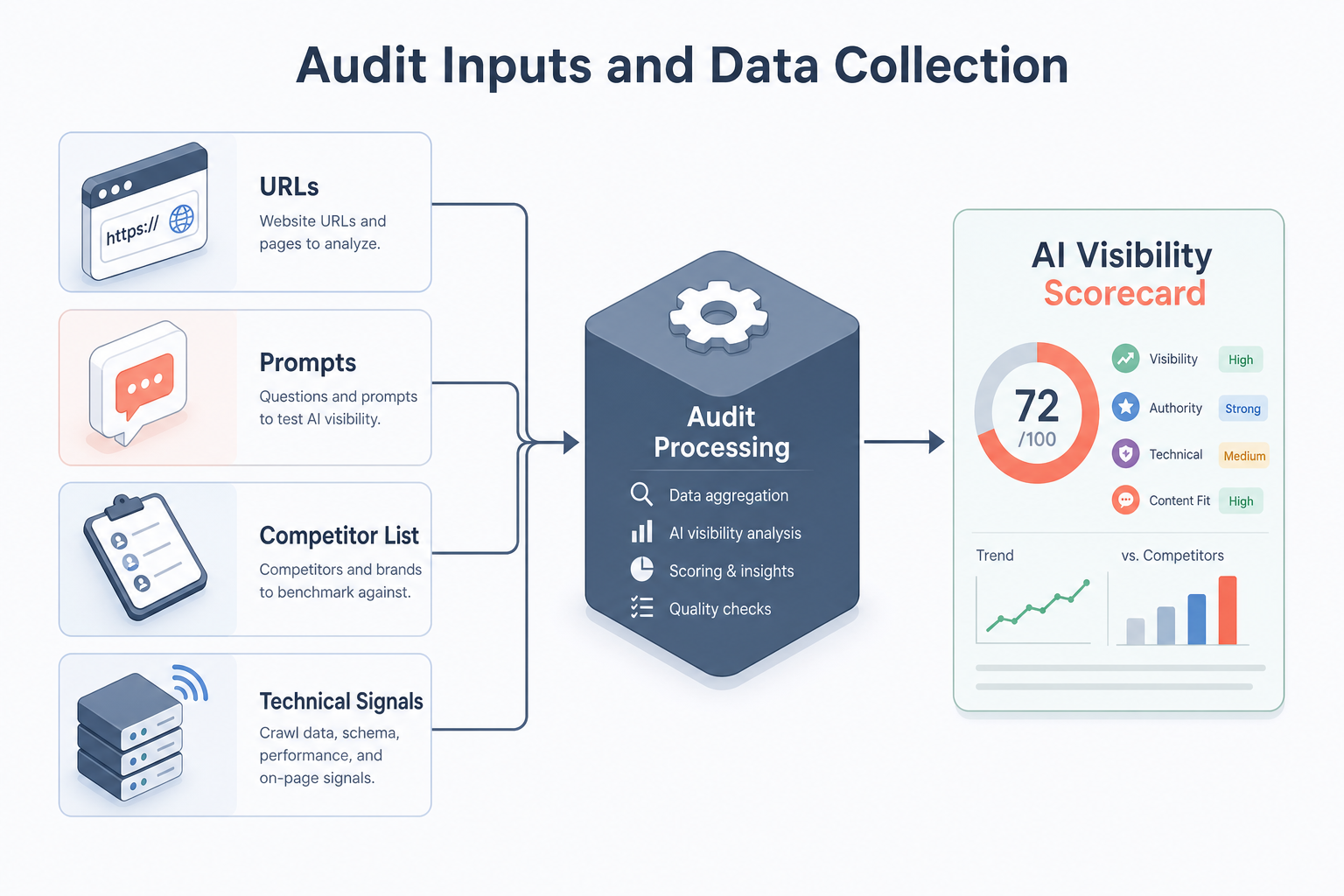
A workflow diagram showing four input streams (URLs, Prompts, Competitor List, Technical Signals) feeding into a central 'Audit Processing' block, resulting in an 'AI Visibility Scorecard'.
Section 1 of 9
Introduction to AI Visibility Data Collection
Transitioning from traditional SEO to AI Visibility (AIV) requires a shift in how we perceive 'data'. In a standard SEO audit, we rely on indexed pages and keyword rankings. In an AI Visibility audit, we must collect data that reflects how Large Language Models (LLMs) ingest, process, and cite information. This lesson focuses on the four pillars of data collection: URL selection, prompt engineering for auditing, competitor identification, and signal mapping.
To audit effectively, you cannot simply 'Google it'. You must simulate the user journey through AI-first interfaces like Perplexity, Gemini, and ChatGPT. This requires a structured approach to inputs to ensure that the audit results are reproducible and actionable for your clients.
Introduction to AI Visibility Data Collection
Lesson Quiz
Pass at 70%.
1. Which of the following should be included in the 'Seed URL' set for an AI audit?
2. What is a 'Zero-Shot Discovery' prompt?
3. Why are 'Information Competitors' important in an AI audit?
4. How many prompts are typically recommended for a baseline AI visibility test?
5. Which signal is most relevant to how an LLM parses data from a webpage?
6. What is the primary risk of only using 'branded' prompts in an audit?
7. In the context of AI Visibility, what is a 'Knowledge Hub'?
8. Why should an auditor include third-party forum links (like Reddit) in their competitor set?
9. What does a 'Citation Request' prompt specifically help you measure?
10. When documenting a baseline for an audit, what is 'Version 0' Reference?