Master the technical and semantic evaluation of content to ensure it is easily parsed, understood, and cited by Generative Engine Optimization (GEO) systems and LLMs.
12 min read
Foundations
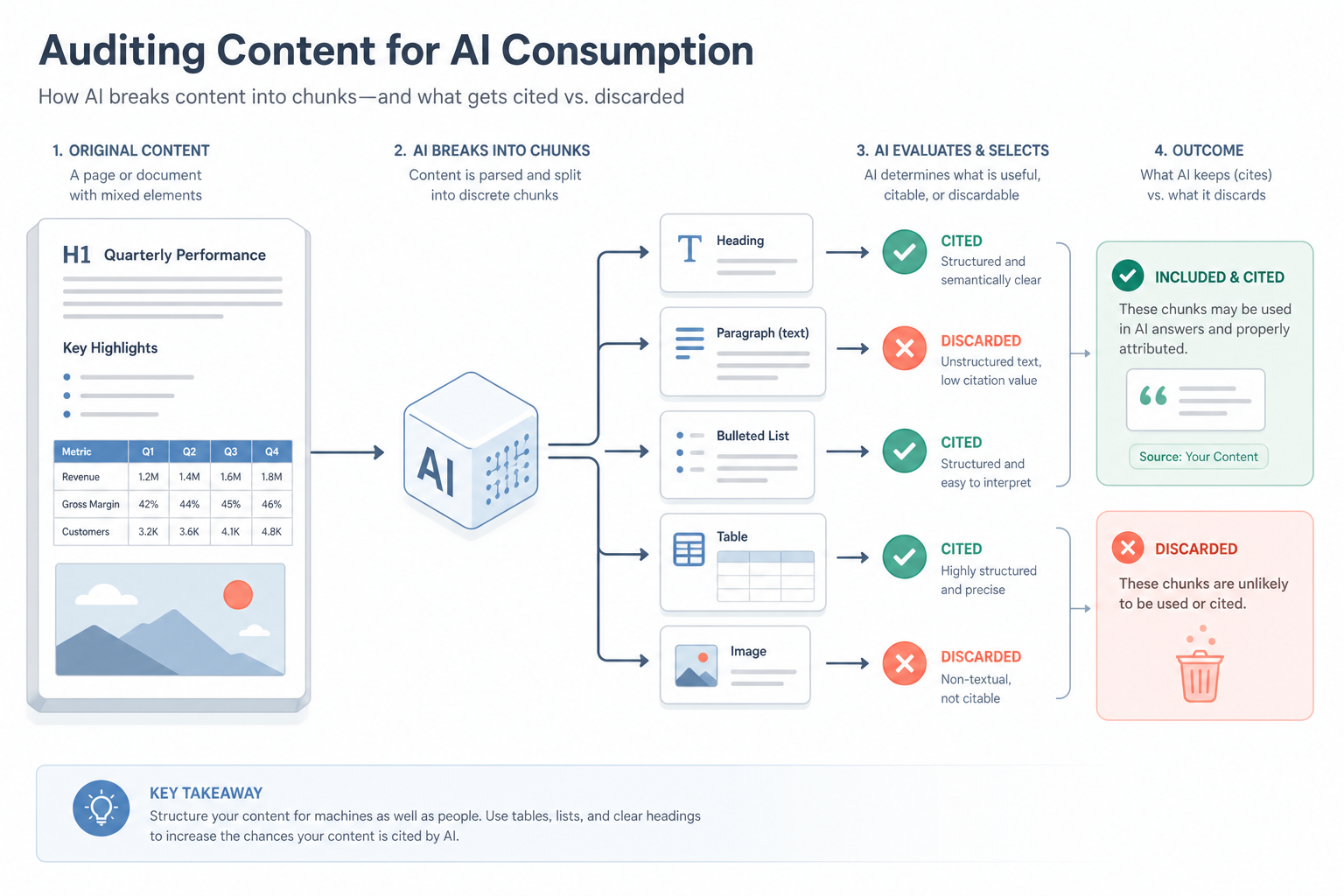
Visual diagram
A flowchart showing a content block being broken into chunks by an AI, where structured elements (tables/lists) are successfully cited while unstructured text and images are discarded.
Section 1 of 10
Introduction to AI Content Auditing
For decades, SEO was about helping a crawler index a page for keyword matching. In the era of AI Visibility, the requirement has evolved. We are no longer just indexing pages; we are feeding a Large Language Model (LLM) information that it must synthesise, attribute, and trust. Auditing content for AI consumption involves evaluating how well a machine can extract facts, maintain the context of those facts, and identify the source for citation. This lesson covers the framework for assessing content through the lens of 'extractability' and 'citable signal'.
Introduction to AI Content Auditing
Lesson Quiz
Pass at 70%.
1. What is the primary goal of auditing content for AI consumption?
2. Which of these elements is most likely to be ignored by an AI trying to provide a factual answer?
3. In the context of AI auditing, what does 'Salience' represent?
4. Why are vague pronouns like 'it' or 'this' problematic for AI visibility?
5. Which header would be most effective for an AI-first content strategy?
6. What is 'Unique Information Gain'?
7. How does Schema.org markup assist in an AI audit?
8. When auditing authoritativeness, what should author bio pages ideally contain?
9. What is a 'Citation Trap' in the context of this lesson?
10. If an LLM identifies your content but attributes it to a generic category, what should you do?