Master the strategic content shifts and authority-building tactics required to convert high-value brand mentions into verifiable citations within AI-driven search results.
12 min read
Foundations
Visual diagram
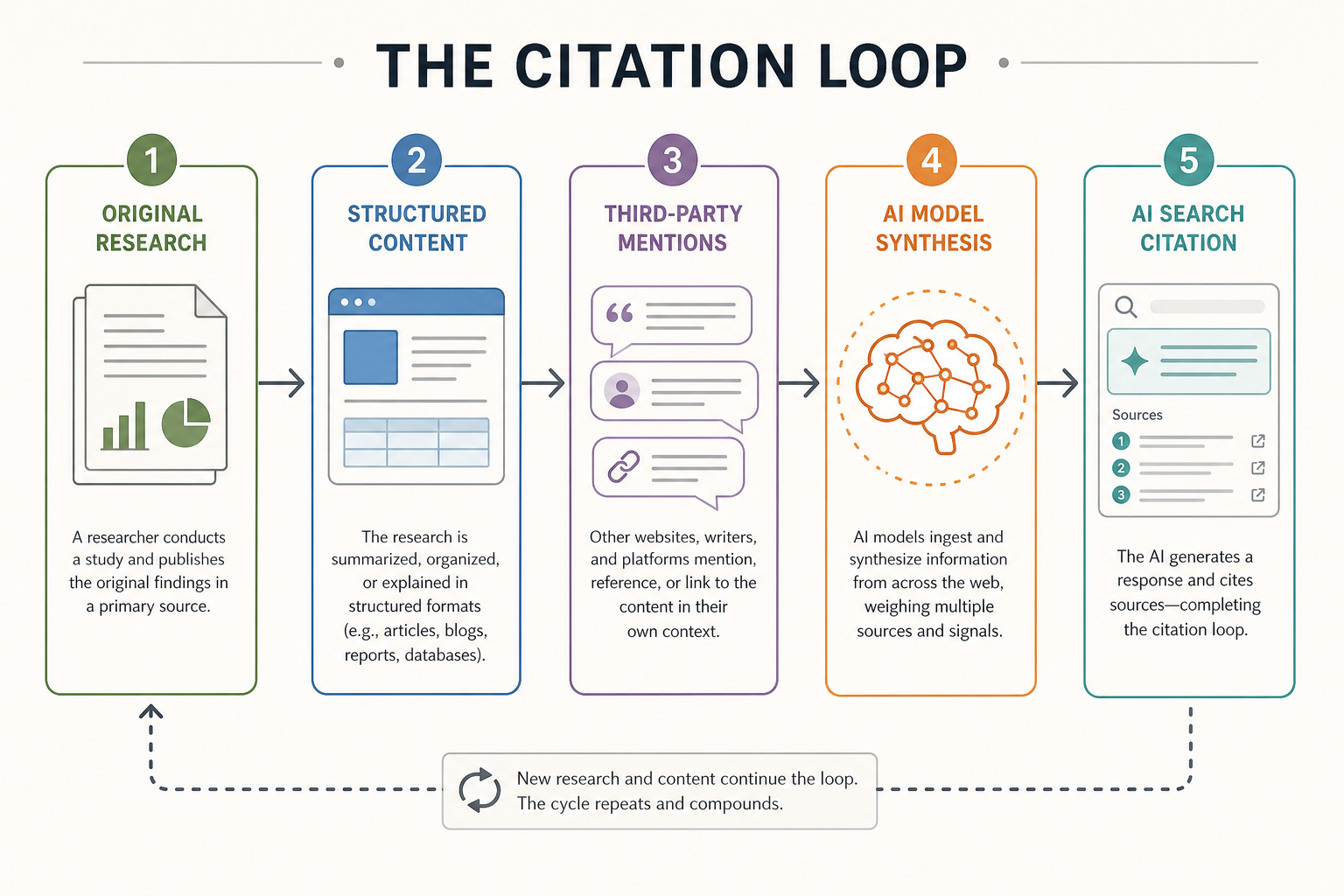
A flowchart showing the 'Citation Loop': from Original Research to Structured Content, then Third-Party Mentions, leading to AI Model Synthesis and finally the AI Search Citation.
Section 1 of 9
Introduction to Earning AI Citations
In the era of Generative Engine Optimisation (GEO), the metric of success is shifting from mere organic rankings to 'citation density'. Unlike traditional backlinks, which rely on a hyperlink for SEO value, AI citations are derived from an LLM's confidence in your brand as a source of truth for a specific query. Earning these citations requires a dual-track strategy: producing 'high-probability' content structures that models can easily parse, and establishing the third-party corroboration that signals authority to the model's training data and retrieval systems.
To earn new citations, practitioners must move beyond generic blogging. We focus on 'Information Gain'—the inclusion of unique data, perspectives, or findings that are not currently present in the top-performing search results. When your content provides the most concise or unique answer to a complex query, you increase the likelihood of the AI synthesising your brand as the primary reference.
Introduction to Earning AI Citations
Lesson Quiz
Pass at 70%.
1. What is 'Information Gain' in the context of AI citations?
2. Which content structure is most likely to be cited by an LLM in a summary?
3. Why are 'Proprietary Metrics' effective for earning citations?
4. What is the primary role of Digital PR in the AI Visibility context?
5. In the 'Inverse Pyramid' style of writing, where should the most citeable fact go?
6. Which schema type is most beneficial for a page containing original research figures?
7. What does the term 'Expertise Echo' refer to?
8. Which of these is a 'declarative sentence' that an AI is likely to cite?
9. How do 'TL;DR' summaries help in AI Citation earning?
10. Why is 'SameAs' schema important for AI attribution?