Learn how to establish a prioritised backlog of AI visibility opportunities using a structured scoring framework to ensure marketing resources focus on high-impact generative engine gains.
12 min read
Foundations
Visual diagram
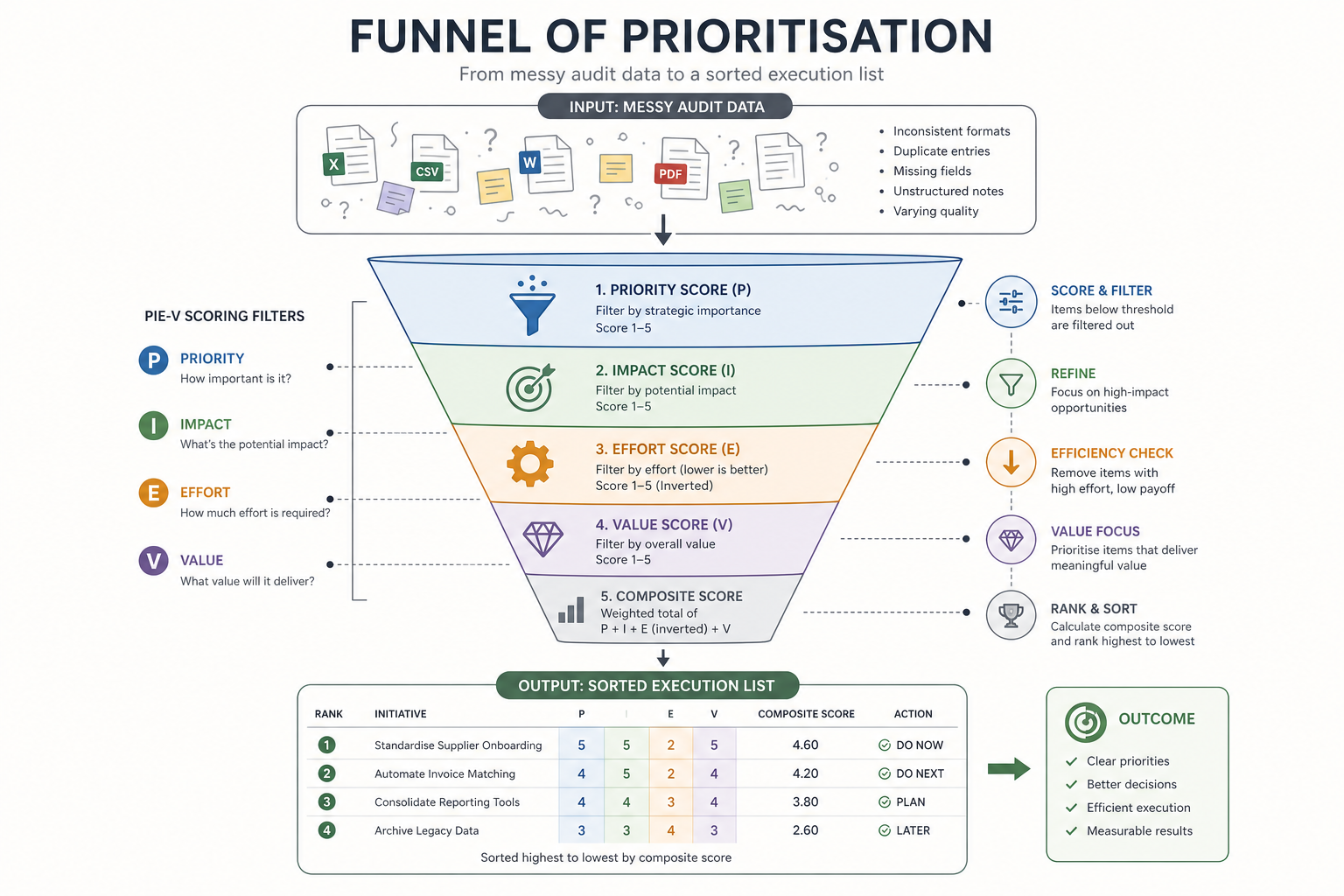
A flow chart showing a 'Funnel of Prioritisation' where messy audit data enters the top, passes through PIE-V scoring filters, and emerges as a sorted execution list.
Section 1 of 9
Introduction
Transitioning from high-level AI visibility concepts to actionable execution requires a central repository of tasks: the Opportunity Backlog. In the context of AI-led search (GEO/AEO), a backlog is not merely a list of keywords to target. Instead, it is a dynamic document that categorises content gaps, technical structured data requirements, and brand citation opportunities. For a practitioner, the backlog is the bridge between strategic audits and tangible results. This lesson details how to construct, score, and maintain a living backlog that your team or client can execute against systematically.
Introduction
Lesson Quiz
Pass at 70%.
1. What is the primary purpose of an Opportunity Backlog in AI visibility?
2. In the PIE-V framework, what does the 'E' stand for?
3. Which category of backlog items involves fixing robots.txt or schema errors?
4. Why is 'Confidence' included in some AI backlog scoring models?
5. How often should an AI Opportunity Backlog ideally be reviewed?
6. What kind of language does the lesson suggest AI engines prefer?
7. When building a backlog, what should you do if a competitor is cited for a query you want?
8. Which task would be considered 'Entity Mapping'?
9. What is the recommended 'wait time' before checking if a change influenced an AI engine?
10. A task with 'Low Ease' and 'Low Impact' should be: