Master the methodology of mapping a subject across brand perception, technical site performance, and Knowledge Graph entity status to define its complete AI visibility footprint.
12 min read
Foundations
Visual diagram
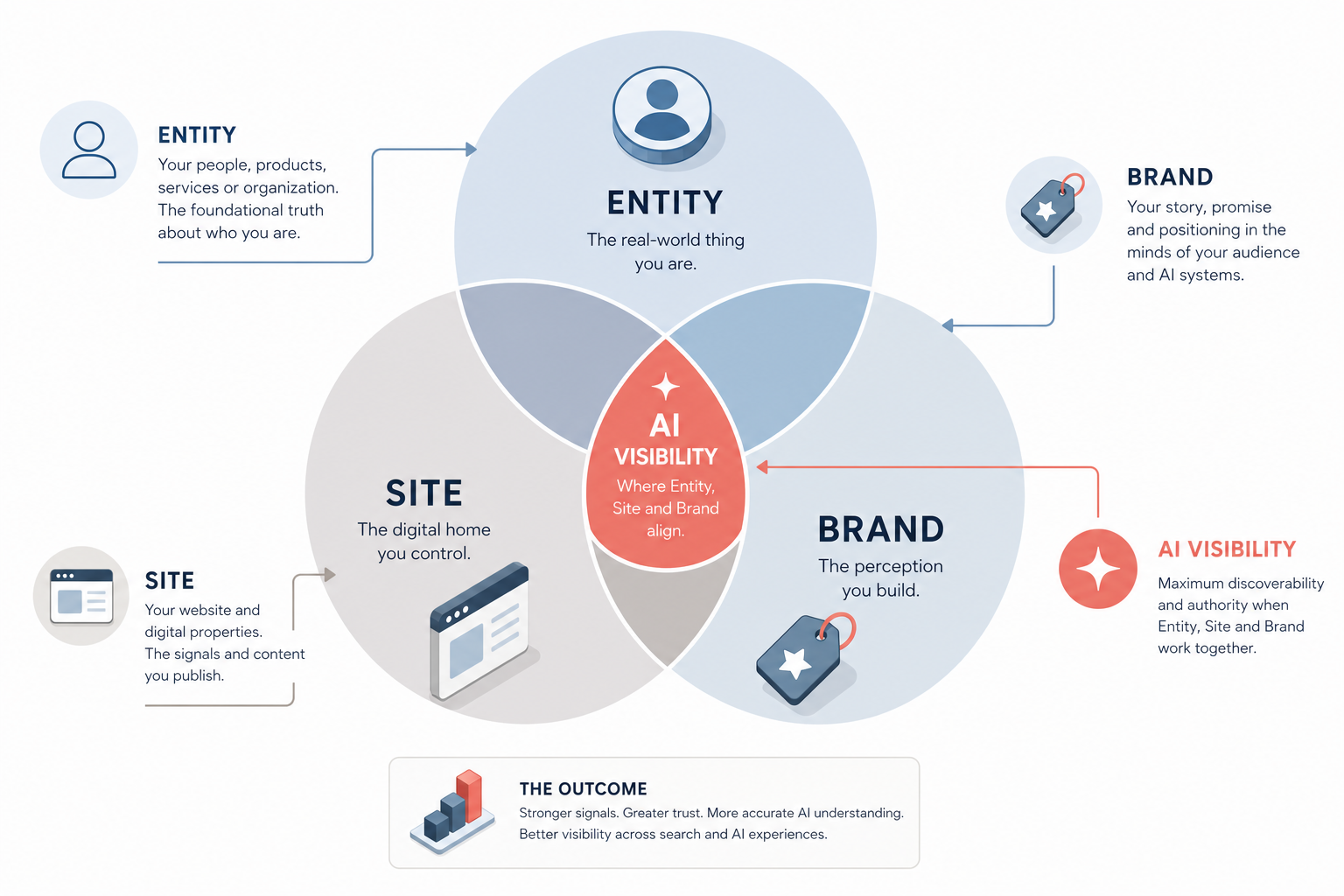
A Venn diagram showing three overlapping circles labeled Entity, Site, and Brand, with 'AI Visibility' at the central intersection where all three align.
Section 1 of 9
Introduction
Transitioning from traditional Search Engine Optimisation (SEO) to AI Visibility requires a shift in how we define the 'subject' of our work. In traditional SEO, we lead with the domain. In the era of Generative Engine Optimisation (GEO) and Answer Engine Optimisation (AEO), we must work across three distinct but overlapping layers: the Brand, the Site, and the Entity. This lesson provides a practitioner's framework for modeling these layers to ensure large language models (LLMs) and retrieval-augmented generation (RAG) systems can accurately identify, verify, and recommend your client.
Introduction
Lesson Quiz
Pass at 70%.
1. What is the primary difference between a Brand and an Entity in AI Visibility?
2. Which Schema.org property is most important for linking a site to its Wikidata entry?
3. What does a search for an entity ID help a practitioner identify?
4. Why are 'unlinked mentions' valuable in the context of AI visibility?
5. In the EcoThread example, why was the hardware company 'Eco-Thread Tools' a problem?
6. Which of these is a component of the 'Site Layer'?
7. What is the danger of having 'Fact Drift' between the Site and the Entity layer?
8. Which tool would you use to find a Wikidata Q-code?
9. What does the 'Corroboration' function of the site layer involve?
10. Which layer is most influenced by PR and external mentions?