Master the specific signals used by ChatGPT, Perplexity, and Gemini to select and verify sources in a generative search environment.
12 min read
Foundations
Visual diagram
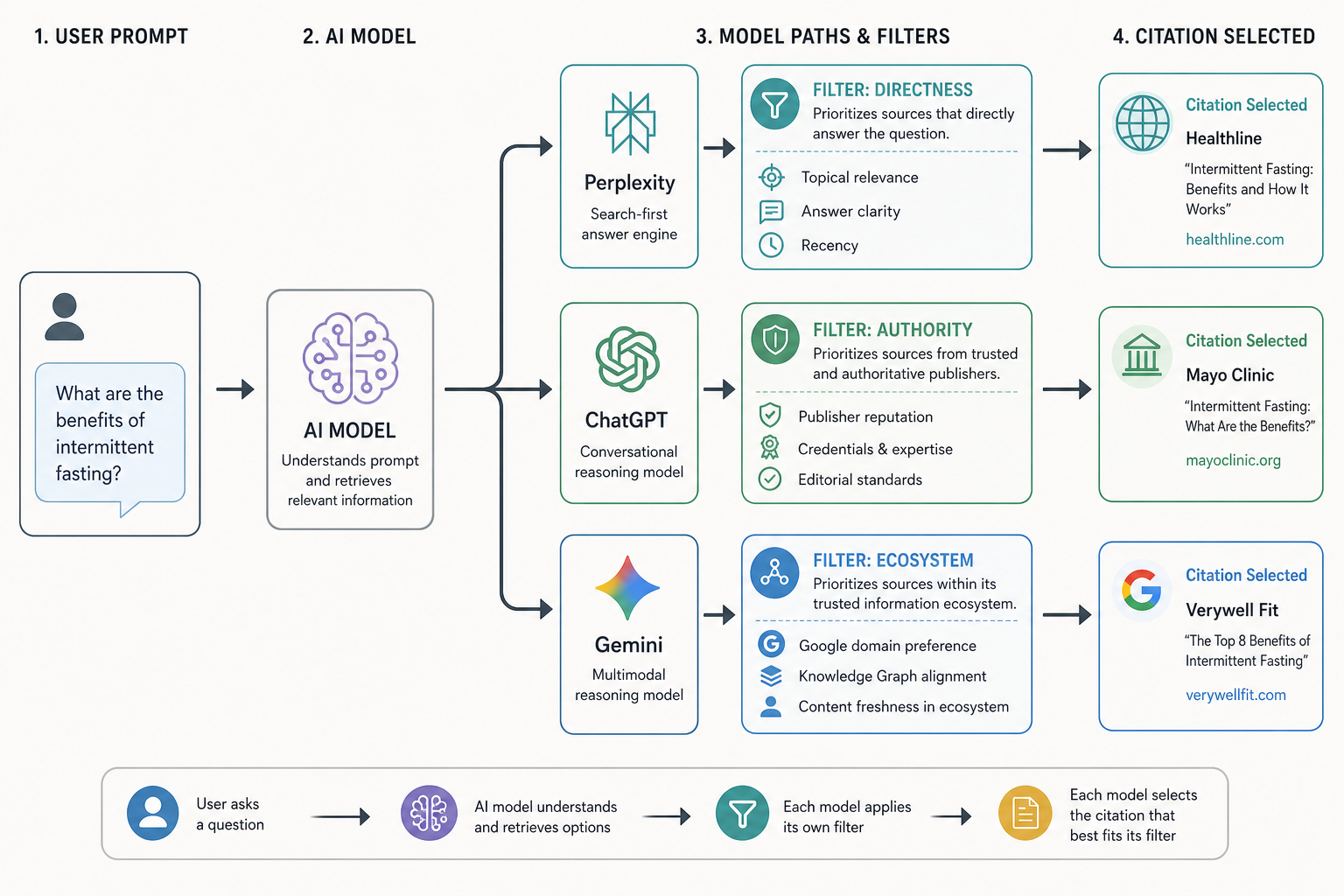
A workflow diagram showing a user prompt entering an AI model, which then splits into three paths (Perplexity, ChatGPT, Gemini), highlighting the different filters each uses (Directness, Authority, Ecosystem) to select a citation.
Section 1 of 7
Introduction
Unlike traditional Google Search, which focuses on ranking a list of documents based on a complex web of backlinks and metadata, AI engines like ChatGPT (OpenAI), Perplexity, and Gemini (Google) act as synthesizers. Their goal is to identify a small subset of the most reliable or relevant sources to present a single, coherent answer. In this lesson, we explore the mechanics of source selection, moving beyond basic SEO to understand the 'Search Augmented Generation' (SAG) and 'Retrieval-Augmented Generation' (RAG) processes that dictate which websites get the coveted citation slot.
Introduction
Lesson Quiz
Pass at 70%.
1. What is the primary process AI engines use to find information before generating a response?
2. Which signal does Perplexity prioritize the most?
3. How does Gemini's source selection differ from ChatGPT?
4. Why are tables and lists effective for AI visibility?
5. What is 'Fact-Density' in the context of citation analysis?
6. What is the second step in the AI's internal process after receiving a prompt?
7. Which schema type would most help Gemini verify an article's points for an AI Overview?
8. In AI visibility, what has largely replaced 'Keyword Matching'?
9. What does ChatGPT (Search) specifically look for to maintain its 'conversational' style?
10. If your brand is mentioned but not linked in an AI response, it is still considered: